
One of the objectives of microservices is to allow independent deployment and scaling of applications. We already learned how to create a UI composition in the previous article of this series. In this article, we’ll learn how to replicate stateful web applications to help supporting high availability, a quality that aims to increase the time an application is available. Although high availability is generally achieved by redundancy, monitoring, and failover, in this article we’ll focus on redundancy at the services level.
Why do we need this?
Stateless applications don’t save client data used in one request for use in a later request. Stateful applications do. Most business web applications are stateful, and this is typically realized by using an HTTP session in the server. This simplifies the development process. For example, in the case of a shopping cart, the items are usually stored on the server-side (in the HTTP session). An alternative to this is to keep the data in the client-side, but this doesn’t allow multiple browser tabs sharing the same shopping cart data and won’t preserve its state if a tab is closed, unless some unreliable workarounds are used with Local Storage.
Replicating a stateful web application makes every instance have its own HTTP session. This is not an issue if all requests for a user session (in the sense of conversation or complete interaction with the web application) are sent to the same instance. However, in case of a failure in the instance, or when requests are not all sent to the same instance, the state is lost. This is illustrated in the following figure:
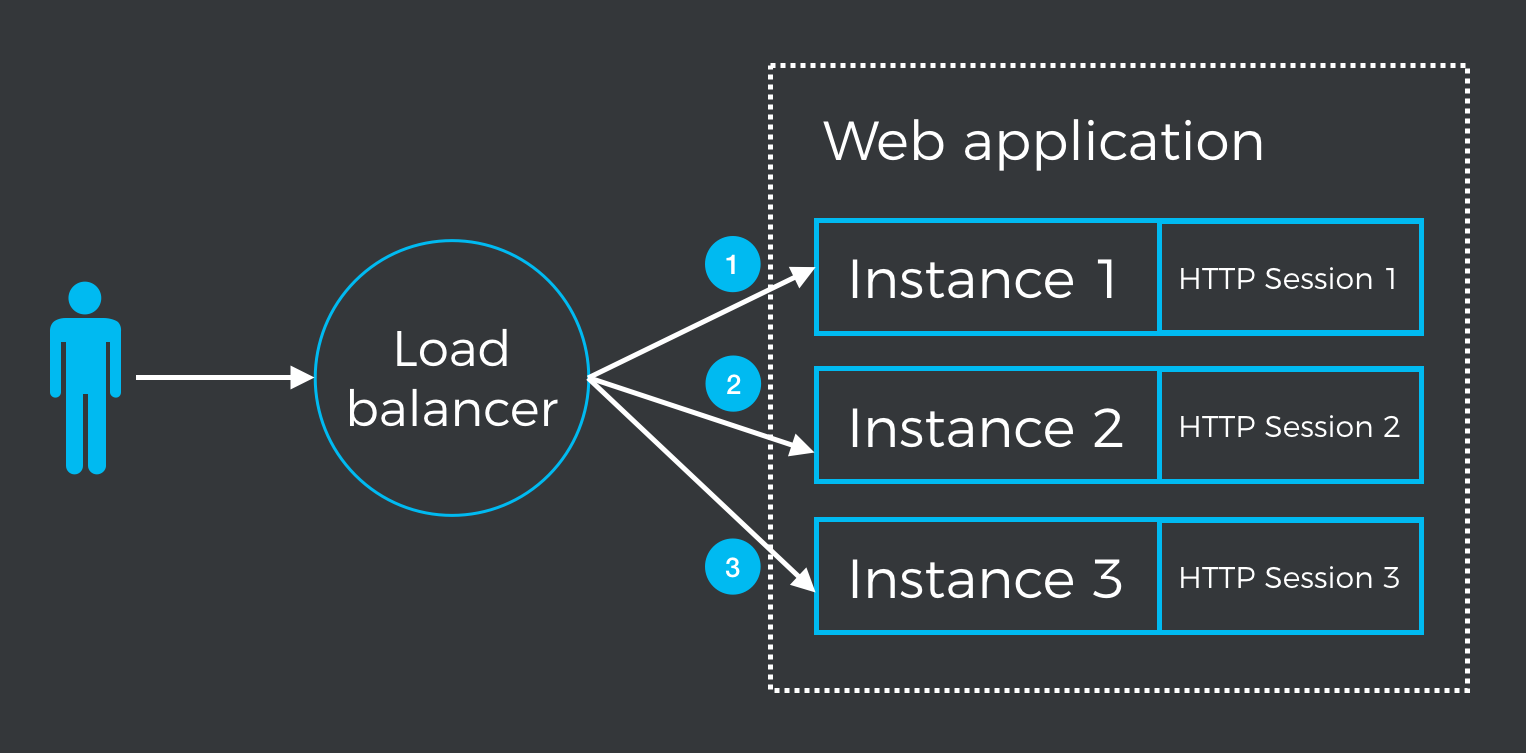
This figure shows three consecutive requests, each one directed to a different instance by a load balancer, resulting in three different states of the application to external viewers. For example, changes to the HTTP session won’t be visible during the second and third requests.
How does it work?
The problem can be solved by externalizing the HTTP session as depicted in the following figure:
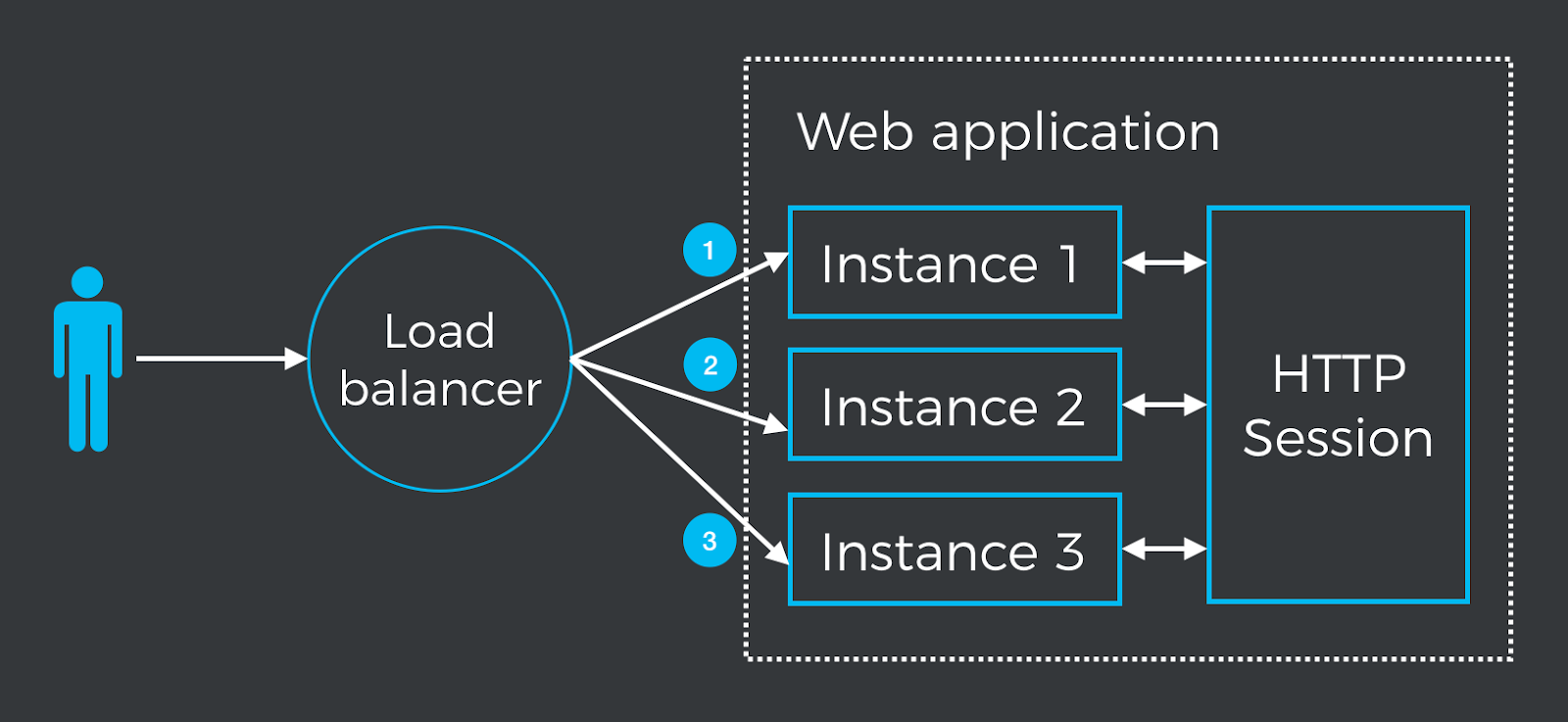
Each instance uses an external HTTP session, allowing them to share the state. When an instance goes down, depending on the strategy used by the load balancer, new requests are directed to other instances, making the unavailability of the failing instance unnoticeable to the user.
Depending on the technologies used, the externalized session can also be replicated to avoid having a single point of failure in the system. However, this requires session replication happening per request, which might be expensive depending on the infrastructure and mechanisms used.
Externalizing the HTTP session with Spring Session
Most Java web servers offer high-availability features that include session replication. Refer to the documentation of Tomcat and Wildfly, if you want to see how to configure session replication with these servers. In this article, we’ll explore how to achieve session replication at the application level using Spring Session, which provides an API that allows replacing the standard HTTP session with an external database. Spring Session includes integration with Redis, JDBC, MongoDB, GemFire, and Hazelcast. To minimize the amount of configuration required, we’ll use Hazelcast with embedded clients in the web application as shown in the following figure:
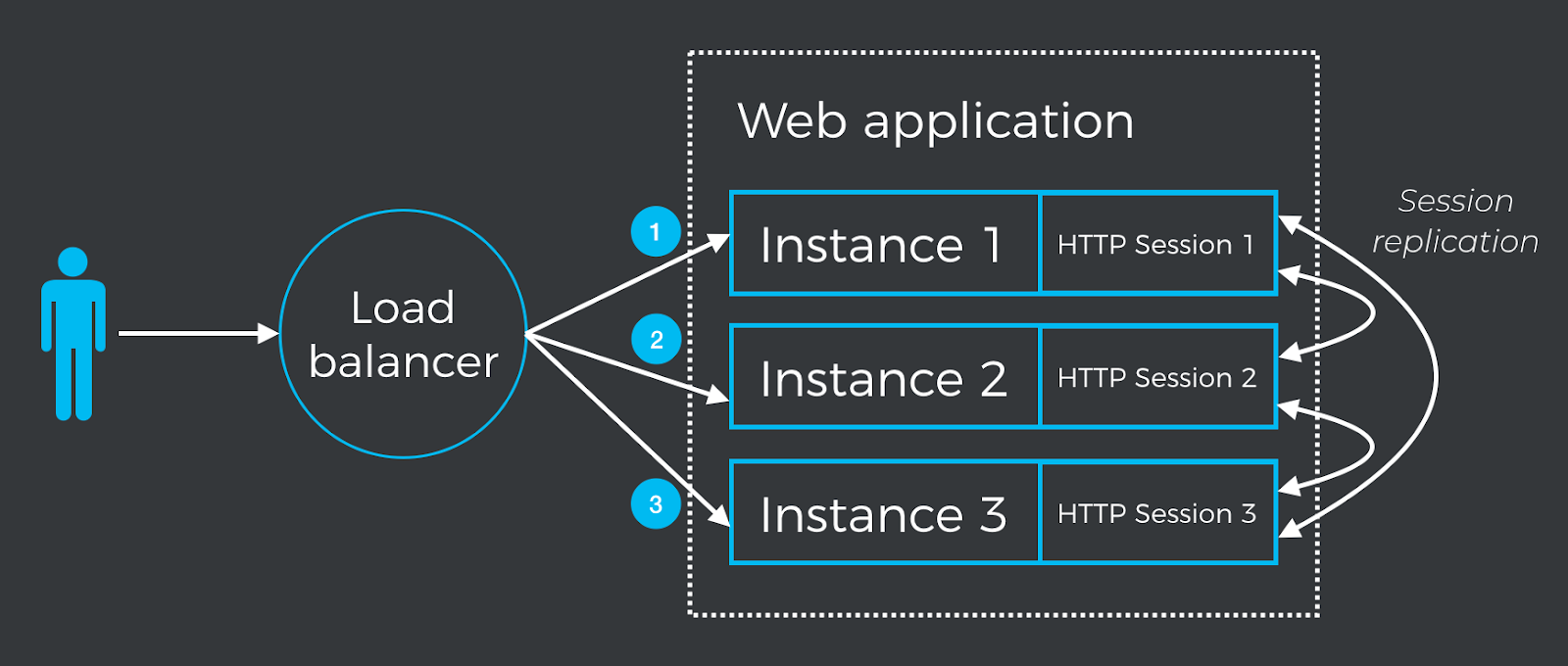
Although the strategy used in the example application replicates the HTTP session with every instance in the cluster, this is not recommended when you increase the number of instances. Always use alternative strategies, such as “buddy replication” (replicating the session only with a “neighbor”), or Tomcat’s Memcached session manager according to your specific network topology, architecture, and requirements.
In order to use Spring Session with Hazelcast, you need to add the following dependency to the pom.xml file of your web application:
<dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-hazelcast</artifactId> </dependency>
To activate Spring Session with Hazelcast, annotate the Spring Boot application class with @EnableHazelcastHttpSession:
...
@EnableHazelcastHttpSession
public class AdminApplication {
...
} You also need to define and configure a bean of type HazelcastInstance:
@Bean
public HazelcastInstance hazelcastInstance() {
MapAttributeConfig attributeConfig = new MapAttributeConfig()
.setName(HazelcastSessionRepository.PRINCIPAL_NAME_ATTRIBUTE)
.setExtractor(PrincipalNameExtractor.class.getName());
Config config = new Config();
config.setProperty("hazelcast.max.no.heartbeat.seconds", 6)
.getMapConfig("spring:session:sessions")
.addMapAttributeConfig(attributeConfig)
.addMapIndexConfig(new MapIndexConfig(HazelcastSessionRepository.PRINCIPAL_NAME_ATTRIBUTE, false));
config.getGroupConfig().setName("admin");
return Hazelcast.newHazelcastInstance(config);
} This code configures a Hazelcast instance running in the same JVM as the web application. Since there are three different web applications (admin-application, news-application, and website-application), and we want to replicate the session only with instances of the same application, we need to set a name for the cluster group.
We are also configuring the heartbeat interval Hazelcast uses to check the connection status between the instances in the cluster. We are using an interval of 6 seconds, suitable for demo purposes, likely not a good configuration for production environments, since this increases the traffic in the network. The default value of 60 seconds is probably a better option for production environments. You can see a more detailed explanation of the required configuration in the Spring Session documentation site.
Feign Clients include non-serializable instances in their implementations. This is a problem if you have references to a Feign-based bean in your UI implementation. This is the case of the admin-application and the news-application. You can solve this by adding a utility class that exposes the problematic service beans through static methods:
@Service
public class Services {
public static CompanyService getCompanyService() {
return getApplicationContext().getBean(CompanyService.class);
}
public static ApplicationContext getApplicationContext() {
ServletContext servletContext = SpringVaadinServlet.getCurrent().getServletContext();
return WebApplicationContextUtils.getWebApplicationContext(servletContext);
}
} Instead of directly injecting beans of type CompanyService, you should call the methods in the service class through the static method as follows:
Services.getCompanyService().findAll()
In the previous article of this series, we introduced a proxy-server that included a load balancer provided by Zuul. By default, Zuul uses a round-robin strategy to forward requests to the available instances. The example application also includes an implementation of a sticky sessions rule for Zuul you can activate using the ribbon.NFLoadBalancerRuleClassName property. This is configurable per application. For example, to enable sticky sessions in the admin-application you can add the following line to the proxy-server.yml configuration file:
admin-application.ribbon.NFLoadBalancerRuleClassName: com.example.StickySessionRule
It is recommended to use sticky sessions when possible and decrease the number of nodes replicating the HTTP session in stateful applications.
In the next article of this series, we’ll discuss a key topic in microservices: Monitoring and health checking.