This article dives deeper into the practical implementation of DDD concepts, with a specific focus on Java and Vaadin – a powerful platform for building modern, secure, and scalable web applications in Java. While the ideas presented here can be applied across programming environments, the examples are tailored to help Java developers effectively adopt these powerful architectural techniques.
The insights in this post are inspired by the foundational books Domain-Driven Design: Tackling Complexity in the Heart of Software by Eric Evans and Implementing Domain-Driven Design by Vaughn Vernon. While these works were the starting point for my journey, the perspectives and code examples here reflect my own practical experiences.
Let’s explore how combining DDD with hexagonal architecture can help you build robust, maintainable, and scalable software solutions.
Table of contents
- What is hexagonal architecture?
- Hexagonal vs. traditional layers
- The domain model in hexagonal architecture
- Application services
- Domain event listeners
- Choosing input and output strategies for application Services
- The role of input validation
- Avoiding God classes: Designing scalable and coherent application services
- Ports and adapters
- Handling communication between multiple bounded contexts
- Next steps
What is hexagonal architecture?
Hexagonal architecture, also known as Ports and Adapters or Onion Architecture, is a design pattern that separates core application logic (the domain model) from external systems and dependencies. The name comes from its typical hexagonal depiction, symbolizing the clean separation between the application’s core and its interfaces.
At the center of this "onion" is the domain model, which contains the core business logic. Surrounding it are layers that interact with infrastructure, external systems, and users via ports and adapters. These intermediaries ensure external changes don’t affect the core logic and vice versa.
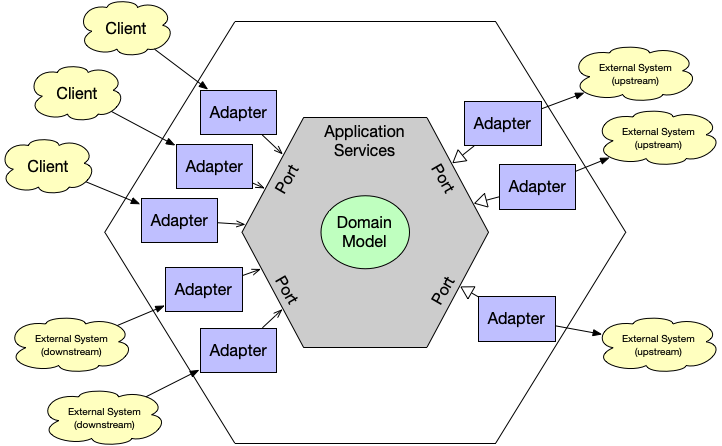
In this article, we’ll explore each layer, starting with the core domain model and working outward to the adapters that connect the application to external systems and clients.
Hexagonal vs. traditional layered architecture
Once we dig deeper into the hexagonal architecture, we will find that it has several resemblances to the more traditional layered architecture. Indeed, you can think of hexagonal architecture as an evolution of layered architecture. However, there are some differences, especially with regard to how a system interacts with the outside world. To better understand these differences, let’s start with a recap of the layered architecture:
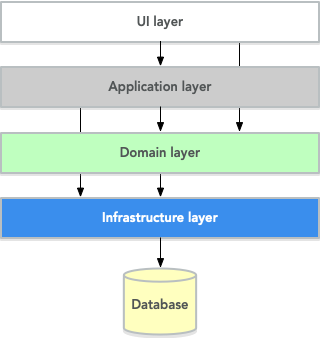
The principle is that the system is built up of layers stacked on top of each other. A higher layer can interact with a lower layer but not the other way around. Typically, in a domain-driven layered architecture, you would have the UI layer at the top. This layer, in turn, interacts with an application service layer, which interacts with the domain model that lives in a domain layer. At the bottom, we have an infrastructure layer that communicates with external systems such as a database.
In the hexagonal system, you will find that the application and domain layers are still pretty much the same. However, the UI layer and the infrastructure layer are treated in very different ways. Keep reading to find out how.
The domain model in hexagonal architecture
At the core of hexagonal architecture lies the domain model, the foundation of your application’s business logic. This is where critical business decisions are made and encapsulated using the building blocks of Tactical Domain-Driven Design (DDD), as covered in our previous article. The domain model is designed to be the most stable part of your software, ideally changing only when your core business requirements evolve.
While we’ve explored the domain model in-depth in earlier parts of this series, it’s essential to emphasize that the domain model alone cannot provide value without mechanisms to interact with it. To enable this interaction, we must look beyond the domain model and explore the next layer in the "onion" architecture, which connects the core logic to the rest of the application.
Application services
An application service acts as a facade through which clients interact with the domain model. Application services have the following characteristics:
-
They are stateless
-
They enforce system security
-
They control the database transactions
-
They orchestrate business operations but do not make any business decisions (i.e., they do not contain any business logic)
Let’s have a closer look at what this means.
Hexagonal vs. Entity-Control-Boundary
Statelessness
An application service does not maintain any internal state that can be changed by interacting with clients. All the information that is needed to perform an operation should be available as input parameters to the application service method. This will make the system simpler and easier to debug and scale.
Suppose you find yourself in a situation where you must make multiple application service calls within a single business process. In that case, you can model the business process in a class of its own and pass an instance of it as an input parameter to the application service method. The method would then do its magic and return an updated instance of the business process object that, in turn, can be used as input to other application service methods:
Business process as input argument
public class MyBusinessProcess {
// Current process state
}
public interface MyApplicationService {
MyBusinessProcess performSomeStuff(MyBusinessProcess input);
MyBusinessProcess performSomeMoreStuff(MyBusinessProcess input);
}
You could also make the business process object mutable and let the application service method change the state of the object directly. I do not prefer this approach since I believe it can lead to unwanted side effects, especially if the transaction rolls back. This depends on how the client is calling the application service, and we will return to this matter later in the section about ports and adapters.
For tips on how to implement more complex and long-running business processes, I encourage you to read Vernon’s book.
Security enforcement
The application service ensures that the current user can perform the operation in question. Technically, you can do this manually at the top of each application service method or use something more sophisticated such as AOP. It does not matter how security is enforced as long as it happens in the application service layer and not inside the domain model. Now, why is this important?
When we talk about security in an application, we tend to emphasize preventing unauthorized access more than permitting authorized access. Thus, any security check we add to the system will essentially make it harder to use. Suppose we add these security checks to the domain model. In that case, we may find ourselves in a situation where we are unable to perform an important operation because we did not think of it when the security checks were added, and now they stand in the way.
By keeping all security checks out of the domain model, we get a more flexible system since we can interact with the domain model in any way we want. The system will still be safe since all clients are required to go through an application service anyway. Creating a new application service is way easier than changing the domain model.
Code Examples
Here are two Java examples of what security enforcement in an application service could look like. The code has not been tested and should be treated more as pseudo-code than actual Java code.
Declarative Security Enforcement
@Service
class MyApplicationService {
@Secured("ROLE_BUSINESS_PROCESSOR") // (1)
public MyBusinessProcess performSomeStuff(MyBusinessProcess input) {
var customer = customerRepository.findById(input.getCustomerId()) // (2)
.orElseThrow( () -> new CustomerNotFoundException(input.getCustomerId()));
var someResult = myDomainService.performABusinessOperation(customer); // (3)
customer = customerRepository.save(customer);
return input.updateMyBusinessProcessWithResult(someResult); // (4)
}
}
-
The annotation instructs the framework only to allow authenticated users with the role
ROLE_BUSINESS_PROCESSORto invoke the method. -
The application service looks up an aggregate root from a repository in the domain model.
-
The application service passes the aggregate root to a domain service in the domain model, storing the result (whatever it is).
-
The application service uses the result of the domain service to update the business process object. It returns it so it can be passed to other application service methods participating in the same long-running process.
Manual Security Enforcement
@Service
class MyApplicationService {
public MyBusinessProcess performSomeStuff(MyBusinessProcess input) {
// We assume SecurityContext is a thread-local class that contains information
// about the current user.
if (!SecurityContext.isLoggedOn()) { // (1)
throw new AuthenticationException("No user logged on");
}
if (!SecurityContext.holdsRole("ROLE_BUSINESS_PROCESSOR")) { // (2)
throw new AccessDeniedException("Insufficient privileges");
}
var customer = customerRepository.findById(input.getCustomerId())
.orElseThrow( () -> new CustomerNotFoundException(input.getCustomerId()));
var someResult = myDomainService.performABusinessOperation(customer);
customer = customerRepository.save(customer);
return input.updateMyBusinessProcessWithResult(someResult);
}
}
-
In a real application, you would probably create helper methods that throw the exception if a user is not logged on. I have only included a more verbose version in this example to show what needs to be checked.
-
As in the previous case, only users with the role
ROLE_BUSINESS_PROCESSORare allowed to invoke the method.
Transaction management
Every application service method should be designed in such a way that it forms a single transaction of its own, regardless of whether the underlying data storage uses transactions or not. If an application service method succeeds, there is no way of undoing it except by explicitly invoking another application service that reverses the operation (if such a method even exists).
If you find yourself in a situation where you would want to invoke multiple application service methods within the same transaction, you should check that the granularity of your application service is correct. Maybe some of the things your application service is doing should actually be in domain services instead. You may also need to consider redesigning your system to use eventual consistency instead of strong consistency (for more information about this, please check the previous article about tactical domain-driven design).
Technically, you can either handle the transactions manually inside the application service method or use the declarative transactions offered by frameworks and platforms such as Spring and Java EE.
Code examples
Here are two Java examples of what transaction management in an application service could look like. The code has not been tested and should be treated more as pseudo-code than actual Java code.
Declarative transaction management
@Service
class UserAdministrationService {
@Transactional // (1)
public void resetPassword(UserId userId) {
var user = userRepository.findByUserId(userId); // (2)
user.resetPassword(); // (3)
userRepository.save(user);
}
}
-
The framework will make sure the entire method runs inside a single transaction. If an exception is thrown, the transaction is rolled back. Otherwise, it is committed when the method returns.
-
The application service calls a repository in the domain model to find the
Useraggregate root. -
The application service invokes a business method on the
Useraggregate root.
Manual transaction management
@Service
class UserAdministrationService {
@Transactional
public void resetPassword(UserId userId) {
var tx = transactionManager.begin(); // (1)
try {
var user = userRepository.findByUserId(userId);
user.resetPassword();
userRepository.save(user);
tx.commit(); // (2)
} catch (RuntimeException ex) {
tx.rollback(); // (3)
throw ex;
}
}
}
-
The transaction manager has been injected into the application service so that the service method can start a new transaction explicitly.
-
If everything works, the transaction is committed after resetting the password.
-
The transaction is rolled back if an error occurs, and the exception is rethrown.
Orchestration
Getting the orchestration right is perhaps the most difficult part of designing a good application service. This is because you need to make sure you are not accidentally introducing business logic into the application service even though you think you are only doing orchestration. So, what does orchestration mean in this context?
By orchestration, I mean looking up and invoking the correct domain objects in the correct order, passing in the correct input parameters, and returning the correct output. In its simplest form, an application service may look up an aggregate based on an ID, invoke a method on that aggregate, save it, and return it. However, in more complex cases, the method may have to look up multiple aggregates, interact with domain services, perform input validation, etc. If you find yourself writing long application service methods, you should ask yourself the following questions:
-
Is the method making a business decision or asking the domain model to make the decision?
-
Should some of the code be moved to domain event listeners?
This being said, having some business logic ending up in an application service method is not the end of the world. It is still pretty close to the domain model and well encapsulated and should be pretty easy to refactor into the domain model at a later time. Don’t waste too much time thinking about whether something should go into the domain model or the application service if it is not immediately clear to you.
Code examples
Here is a Java example of what a typical orchestration could look like. The code has not been tested and should be treated more as pseudo-code than actual Java code.
Orchestration involving multiple domain objects
@Service
class CustomerRegistrationService {
@Transactional // (1)
@PermitAll // (2)
public Customer registerNewCustomer(CustomerRegistrationRequest request) {
var violations = validator.validate(request); // (3)
if (violations.size() > 0) {
throw new InvalidCustomerRegistrationRequest(violations);
}
customerDuplicateLocator.checkForDuplicates(request); // (4)
var customer = customerFactory.createNewCustomer(request); // (5)
return customerRepository.save(customer); // (6)
}
}
-
The application service method runs inside a transaction.
-
The application service method can be accessed by any user.
-
We invoke a JSR-303 validator to check that the incoming registration request contains all the necessary information. If the request is invalid, we throw an exception that will be reported to the user.
-
We invoke a domain service that will check if a customer is in the database with the same information. If that is the case, the domain service will throw an exception (not shown here) that will be propagated back to the user.
-
We invoke a domain factory that will create a new
Customeraggregate with information from the registration request object. -
We invoke a domain repository to save the customer and return the newly created and saved customer aggregate root.
Domain event listeners
In the previous article about tactical domain-driven design, we talked about domain events and domain event listeners. We did not, however, talk about where the domain event listeners fit into the overall system architecture. We recall from the previous article that a domain event listener should not be able to affect the outcome of the method that published the event in the first place. In practice, this means that a domain event listener should run inside its transaction.
Because of this, I consider domain event listeners to be a special application service invoked not by a client but by a domain event. In other words, domain event listeners belong in the application service layer and not inside the domain model. This also means that a domain event listener is an orchestrator that should not contain any business logic. Depending on what needs to happen when a certain domain event is published, you may have to create a separate domain service that decides what to do with it if there is more than one path forward.
This being said, in the section about aggregates in the previous article, I mentioned that it might sometimes be justified to alter multiple aggregates within the same transaction, even though this goes against the aggregate design guidelines. I also mentioned that this should preferably be made through domain events. In cases like this, the domain event listeners would have to participate in the current transaction, which could affect the outcome of the method that published the event, breaking the design guidelines for both domain events and application services. This is not the end of the world as long as you do it intentionally and are aware of the consequences you might face in the future. Sometimes you have to be pragmatic.
Choosing input and output strategies for application services
-
Use the entities and value objects directly from the domain model.
-
Use separate Data Transfer Objects (DTOs).
-
Use Domain Payload Objects (DPOs) that are a combination of the two above.
Each alternative has its pros and cons, so let’s have a closer look at each.
Entities and aggregates
In the first alternative, the application services return entire aggregates (or parts thereof). The client can do whatever it wants with them, and when it is time to save changes, the aggregates (or parts thereof) are passed back to the application service as parameters.
This alternative works best when the domain model is anemic (i.e., it only contains data and no business logic) and the aggregates are small and stable (as in unlikely to change much in the near future).
It also works if the client will be accessing the system through REST or SOAP, and the aggregates can easily be serialized into JSON or XML and back. In this case, clients will not actually be interacting directly with your aggregates but with a JSON or XML representation of the aggregate that may be implemented in a completely different language. From the client’s perspective, the aggregates are just DTOs.
The advantages of this alternative are:
-
You can use the classes that you already have
-
There is no need to convert between domain objects and DTOs.
The disadvantages are:
-
It couples the domain model directly to the clients. If the domain model changes, you must also change your clients.
-
It imposes restrictions on how you validate user input (more about this later).
-
You have to design your aggregates in such a way that the client cannot put the aggregate into an inconsistent state or perform an operation that is not allowed.
-
You may run into problems with the lazy loading of entities inside an aggregate (JPA).
Personally, I try to avoid this approach as much as I can.
Data Transfer Objects (DTOs)
In the second alternative, the application services consume and return data transfer objects. The DTOs can correspond to entities in the domain model. Still, more often, they are designed for a specific application service or even a specific application service method (such as request and response objects). The application service is then responsible for moving data back and forth between the DTOs and the domain objects.
This alternative works best when the domain model is very rich in business logic, the aggregates are complex, or the domain model is expected to change a lot while keeping the client API as stable as possible.
The advantages of this alternative are:
-
The clients are decoupled from the domain model, making it easier to evolve without changing the clients.
-
Only the data that is actually needed is being passed between the clients and the application services, improving performance (especially if the client and the application service are communicating over a network in a distributed environment).
-
It becomes easier to control access to the domain model, especially if only certain users are allowed to invoke certain aggregate methods or view certain aggregate attribute values.
-
Only application services will interact with the aggregates inside active transactions. This means you can utilize lazy loading of entities inside an aggregate (JPA).
-
You get even more flexibility if the DTOs are interfaces and not classes.
The disadvantages are:
-
You get a new set of DTO classes to maintain.
-
You have to move data back and forth between DTOs and aggregates. This can be especially tedious if the DTOs and entities are almost similar in structure. If you work in a team, you need a good explanation for why the separation of DTOs and aggregates is warranted.
Personally, I start with this approach in most cases. Sometimes, I end up converting my DTOs into DPOs, which is the next alternative we will look at.
Domain Payload Objects (DPOs)
In the third alternative, application services consume and return domain payload objects. A domain payload object is a data transfer object that is aware of the domain model and can contain domain objects. This is essentially a combination of the first two alternatives.
This alternative works best in cases where the domain model is anemic, the aggregates are small and stable, and you want to implement an operation that involves multiple different aggregates. I would say I use DPOs more often as output objects than input objects. However, I try to limit the use of domain objects in DPOs to value objects if only possible.
The advantages of this alternative are:
-
You do not need to create DTO classes for everything. You do it when passing a domain object directly to the client is good enough. When you need a custom DTO, you create one. When you need both, you use both.
The disadvantages are:
-
Same as for the first alternative. The disadvantages can be mitigated by only including immutable value objects inside the DPOs.
Code examples
Here are two Java examples of using DTOs and DPOs, respectively. The DTO example demonstrates a use case where it makes sense to use a DTO than return the entity directly: Only a fraction of the entity attributes are needed, and we need to include information that does not exist in the entity. The DPO example demonstrates a use case where it makes sense to use a DPO: We need to include many different aggregates that are related to each other in some way.
The code has not been tested and should be treated more as pseudo-code than actual Java code.
Data Transfer Object (DTO) example
public class CustomerListEntryDTO { // (1)
private CustomerId id;
private String name;
private LocalDate lastInvoiceDate;
// Getters and setters omitted
}
@Service
public class CustomerListingService {
@Transactional
public List<CustomerListEntryDTO> getCustomerList() {
var customers = customerRepository.findAll(); // (2)
var dtos = new ArrayList<CustomerListEntryDTO>();
for (var customer : customers) {
var lastInvoiceDate = invoiceService.findLastInvoiceDate(customer.getId()); // (3)
dto = new CustomerListEntryDTO(); // (4)
dto.setId(customer.getId());
dto.setName(customer.getName());
dto.setLastInvoiceDate(lastInvoiceDate);
dtos.add(dto);
}
return dto;
}
}
-
The Data Transfer Object is just a data structure without any business logic. This particular DTO is designed to be used in a user interface list view that only needs to show the customer name and last invoice date.
-
We look up all the customer aggregates from the database. This would be a paginated query in a real-world application that only returns a subset of the customers.
-
The last invoice date is not stored in the customer entity, so we have to invoke a domain service to look it up for us.
-
We create the DTO instance and populate it with data.
Domain Payload Object (DPO) example
public class CustomerInvoiceMonthlySummaryDPO { // (1)
private Customer customer;
private YearMonth month;
private Collection<Invoice> invoices;
// Getters and setters omitted
}
@Service
public class CustomerInvoiceSummaryService {
public CustomerInvoiceMontlySummaryDPO getMonthlySummary(CustomerId customerId, YearMonth month) {
var customer = customerRepository.findById(customerId); // (2)
var invoices = invoiceRepository.findByYearMonth(customerId, month); // (3)
var dpo = new CustomerInvoiceMonthlySummaryDPO(); // (4)
dpo.setCustomer(customer);
dpo.setMonth(month);
dpo.setInvoices(invoices);
return dpo;
}
}
-
The Domain Payload Object is a data structure without any business logic that contains both domain objects (in this case, entities) and additional information (in this case, the year and month).
-
We fetch the customer’s aggregate root from the repository.
-
We fetch the customer’s invoices for the specified year and month.
-
We create the DPO instance and populate it with data.
The role of input validation
As we have mentioned previously, an aggregate must always be in a consistent state. This means, among other things, that we need to properly validate all the input used to alter an aggregate's state. How and where do we do that?
From a user experience perspective, the UI should validate inputs to prevent invalid operations. However, relying simply on user interface validation is not good enough in a hexagonal system. The reason for this is that the user interface is but one of the potentially many entry points into the system. It does not help that the user interface is validating data properly if a REST endpoint lets any garbage through to the domain model.
There are two types of input validation:
- Format validation: Ensures values conform to predefined patterns (e.g., valid email addresses or social security numbers).
- Content validation: Check that well-formed data makes logical sense (e.g., verifying a social security number belongs to a real person).
You can implement these validations in different ways, so let’s have a closer look.
Format validation
If you are using a lot of value objects in your domain model that are wrappers around primitive types (such as strings or integers), then it makes sense to build the format validation straight into your value object constructor.
In other words, it should not be possible to create, e.g., an EmailAddress or SocialSecurityNumber instance without passing in a well-formed argument. This has the added advantage that you can do some parsing and cleaning up inside the constructor if there are multiple known ways of entering valid data (e.g., when entering a phone number, some people may use spaces or dashes to split the number into groups whereas others may not use any whitespace at all).
When the value objects are valid, how do we validate the entities that use them? There are two options available for Java developers:
- Constructor and setter validation: Add the validation into your constructors, factories, and setters to prevent aggregates from reaching an inconsistent state. All required fields must be populated in the constructor, any setters of required fields will not accept null parameters, other setters will not accept values of an incorrect format or length, etc. I tend to use this approach when working with domain models that are very rich in business logic. It makes the domain model very robust but also practically forces you to use DTOs between clients and application services since it is more or less impossible to bind properly to a UI.
- Java Bean Validation (JSR-303): Use annotations on all fields and ensure your application service runs the aggregate through the
Validatorbefore doing anything else with it. I personally tend to use this approach when I’m working with domain models that are anemic. Even though the aggregate itself does not prevent anybody from putting it into an inconsistent state, you can safely assume that all aggregates that have either been retrieved from a repository or have passed validation are consistent.
Both methods can be combined, applying constructor-level validation for domain models and JSR-303 validation for incoming DTOs or DPOs.
Content validation
The simplest case of content validation is to make sure that two or more interdependent attributes within the same aggregate are valid (e.g., if one attribute is set, the other must be null and vice versa). You can either implement this directly into the entity class itself or use a class-level Java Bean Validation constraint. This type of content validation will come for free while performing format validation since it uses the same mechanisms.
A more complex case of content validation would be to check that a certain value exists (or does not exist) in a lookup list somewhere. This is very much the responsibility of the application service. Before allowing any business or persistence operations to continue, the application service should perform the lookup and throw an exception if needed. This is not something you want to put into your entities since the entities are movable domain objects. In contrast, the objects needed for the lookup are typically static (see the previous article about tactical DDD for more information about movable and static objects).
The most complex content validation case would be verifying an entire aggregate against a set of business rules. In this case, the responsibility is split between the domain model and the application service. A domain service would be responsible for performing the validation itself, but the application service would be responsible for invoking the domain service.
Code examples
Here, we are going to look at three different ways of handling validation. In the first case, we will look at performing format validation inside the constructor of a value object (a phone number). In the second case, we will look at an entity with built-in validation so that it is impossible to put the object into an inconsistent state in the first place. In the third and last case, we will look at the same entity but implemented using JSR-303 validation. That makes it possible to put the object into an inconsistent state but not to save it to the database as such.
Value object with format validation
public class PhoneNumber implements ValueObject {
private final String phoneNumber;
public PhoneNumber(String phoneNumber) {
Objects.requireNonNull(phoneNumber, "phoneNumber must not be null"); // (1)
var sb = new StringBuilder();
char ch;
for (int i = 0; i < phoneNumber.length(); ++i) {
ch = phoneNumber.charAt(i);
if (Character.isDigit(ch)) { // (2)
sb.append(ch);
} else if (!Character.isWhitespace(ch) && ch != '(' && ch != ')' && ch != '-' && ch != '.') { // (3)
throw new IllegalArgument(phoneNumber + " is not valid");
}
}
if (sb.length() == 0) { // (4)
throw new IllegalArgumentException("phoneNumber must not be empty");
}
this.phoneNumber = sb.toString();
}
@Override
public String toString() {
return phoneNumber;
}
// Equals and hashCode omitted
}
-
First, we check that the input value is not null.
-
We include only digits in the final phone number that we actually store. For international phone numbers, we should also support a '+' sign as the first character, but we’ll leave that as an exercise to the reader.
-
We allow but ignore whitespace and certain special characters that people often use in phone numbers.
-
Finally, when all the cleaning is done, we check that the phone number is not empty.
An entity with built-in validation
public class Customer implements Entity {
// Fields omitted
public Customer(CustomerNo customerNo, String name, PostalAddress address) {
setCustomerNo(customerNo); // (1)
setName(name);
setPostalAddress(address);
}
public setCustomerNo(CustomerNo customerNo) {
this.customerNo = Objects.requireNonNull(customerNo, "customerNo must not be null");
}
public setName(String name) {
Objects.requireNonNull(nanme, "name must not be null");
if (name.length() < 1 || name.length > 50) { // (2)
throw new IllegalArgumentException("Name must be between 1 and 50 characters");
}
this.name = name;
}
public setAddress(PostalAddress address) {
this.address = Objects.requireNonNull(address, "address must not be null");
}
}
-
We invoke the setters from the constructor in order to perform the validation implemented in the setter methods. There is a small risk in invoking overridable methods from a constructor in case a subclass decides to override any of them. In this case, marking the setter methods as final would be better, but some persistence frameworks may have a problem with that. You just have to know what you are doing.
-
Here we check the length of a string. The lower limit is a business requirement since every customer must have a name. The upper level is a database requirement since the database, in this case, has a schema that only allows it to store strings of 50 characters. By adding the validation here already, you can avoid annoying SQL errors at a later stage when you try to insert too long strings into the database.
An entity with JSR-303 validation
public class Customer implements Entity {
@NotNull (1)
private CustomerNo customerNo;
@NotBlank (2)
@Size(max = 50) (3)
private String name;
@NotNull
private PostalAddress address;
// Setters omitted
}
-
This annotation ensures that the customer number cannot be null when the entity is saved.
-
This annotation ensures that the name cannot be empty or null when the entity is saved.
-
This annotation ensures that the name cannot be longer than 50 characters when the entity is saved.
Avoiding god classes: Designing scalable and coherent application services
Before we go on to ports and adapters, there is one more thing I want to mention briefly. As with all facades, there is an ever-present risk of the application services growing into huge god classes that know too much and do too much. These types of classes are often hard to read and maintain simply because they are so large.
So, how do you keep the application services small? The first step is to split a service that is growing too big into smaller services. However, there is a risk in this as well. I have seen situations where two services were so similar that developers did not know what the difference was between them nor which method should go into which service. The result was that service methods were scattered over two separate service classes and sometimes even implemented twice - once in each service - but by different developers.
When I design application services, I try to make them as coherent as possible. In CRUD applications, this could mean one application service per aggregate. In more domain-driven applications, this could mean one application service per business process or even separate services for specific use cases or user interface views.
Naming is a very good guideline when designing application services. Try to name your application services according to what they do as opposed to which aggregates they concern. E.g. EmployeeCrudService or EmploymentContractTerminationUsecase are far better names than EmployeeService which could mean anything. Also, consider your naming conventions: do you need to end all your services with the Service suffix? Would it make more sense in some cases to use suffixes such as Usecase or Orchestrator or even leave the suffix out completely?
Finally, I want to mention command-based application services. In this case, you model each application service model as a command object with a corresponding command handler. This means that every application service contains exactly one method that handles exactly one command. You can use polymorphism to create specialized commands or command handlers. This approach results in a large number of small classes. It is useful, especially in applications whose user interfaces are inherently command-driven or where clients interact with application services through some kind of messaging mechanisms such as a message queue (MQ) or enterprise service bus (ESB).
Code examples
I’m not going to give you an example of what a God-class looks like because that would take up too much space. Besides, I think most developers who have been in the profession for a while have seen their fair share of such classes. Instead, we are going to look at an example of what a command-based application service could look like. The code has not been tested and should be treated more as pseudo-code than actual Java code.
Command-based application services
public interface Command<R> { // (1)
}
public interface CommandHandler<C extends Command<R>, R> { // (2)
R handleCommand(C command);
}
public class CommandGateway { // (3)
// Fields omitted
public <C extends Command<R>, R> R handleCommand(C command) {
var handler = commandHandlers.findHandlerFor(command)
.orElseThrow(() -> new IllegalStateException("No command handler found"));
return handler.handleCommand(command);
}
}
public class CreateCustomerCommand implements Command<Customer> { // (4)
private final String name;
private final PostalAddress address;
private final PhoneNumber phone;
private final EmailAddress email;
// Constructor and getters omitted
}
public class CreateCustomerCommandHandler implements CommandHandler<CreateCustomerCommand, Customer> { // (5)
@Override
@Transactional
public Customer handleCommand(CreateCustomerCommand command) {
var customer = new Customer();
customer.setName(command.getName());
customer.setAddress(command.getAddress());
customer.setPhone(command.getPhone());
customer.setEmail(command.getEmail());
return customerRepository.save(customer);
}
}
-
The
Commandinterface is just a marker interface that also indicates the result (output) of the command. If the command has no output, the result can beVoid. -
The
CommandHandlerinterface is implemented by a class that knows how to handle (perform) a particular command and return the result. -
Clients interact with a
CommandGatewayto avoid having to look up individual command handlers. The gateway knows about all available command handlers and how to find the correct one based on any given command. The code for looking up handlers is not included in the example since it depends on the underlying mechanism for registering handlers. -
Every command implements the
Commandinterface and includes all the necessary information to perform the command. I like to make my commands immutable with built-in validation, but you can also make them mutable and use JSR-303 validation. You can even leave your commands as interfaces and let the clients implement them themselves for maximum flexibility. -
Every command has its own handler that performs the command and returns the result.
Ports and adapters
So far, we have discussed the domain model and the application services that surround and interact with it. However, these application services are completely useless if there is no way for clients to invoke them; that is where ports and adapters enter the picture.
What is a port?
A port is an interface between the system and the outside world that has been designed for a particular purpose or protocol. Ports are not only used to allow outside clients to access the system but also to allow the system to access external systems.
Now, it is easy to start thinking of the ports as network ports and the protocols as network protocols, such as HTTP. I made this mistake myself, and in fact, Vernon does that, too, in at least one example in his book. However, if you look closer at the article by Alistair Cockburn that Vernon refers to, you will find this is not the case. It is, in fact, far more interesting than that.
A port is a technology-agnostic application programming interface (API) that has been designed for a particular type of interaction with the application (hence the word "protocol"). How you define this protocol is completely up to you, making this approach exciting. Here are a few examples of different ports you may have:
-
A port used by your application to access a database
-
A port used by your application to send out messages such as e-mails or text messages
-
A port used by human users to access your application
-
A port used by other systems to access your application
-
A port used by a particular user group to access your application
-
A port exposing a particular use case
-
A port designed for polling clients
-
A port designed for subscribing clients
-
A port designed for synchronous communication
-
A port designed for asynchronous communication
-
A port designed for a particular type of device
This list is by no means exhaustive, and I’m sure you can come up with many more examples yourself. You can also combine these types. For example, you could have a port that allows administrators to manage users using a client that uses asynchronous communication. You can add as many ports to the system as you want or need without affecting the other ports or the domain model.
Let’s have a look at the hexagonal architecture diagram again:
Each side of the inner hexagonal represents a port. This is the reason why this architecture is often depicted like this: you get six sides out-of-the-box that you can use for different ports and plenty of room to draw in as many adapters as you need. But what is an adapter?
What is an adapter?
I already mentioned that ports are technology-agnostic. Still, you interact with the system through some technology - a web browser, a mobile device, a dedicated hardware device, a desktop client, and so on. This is where adapters come in.
An adapter allows interaction through a particular port using a particular technology. For example:
-
A REST adapter allows REST clients to interact with the system through some port
-
A RabbitMQ adapter allows RabbitMQ clients to interact with the system through some port
-
An SQL adapter allows the system to interact with a database through some port
-
A Vaadin adapter allows human users to interact with the system through some port
You can have multiple adapters for a single port or even a single adapter for multiple ports. You can add as many adapters to the system as you want or need without affecting the other adapters, the ports, or the domain model.
Ports and adapters in code
By now, you should have some idea of what a port and an adapter are on a conceptual level. But how do you transform these concepts into code? Let’s have a look!
Ports will, in most cases, materialize themselves as interfaces in your code. For ports that allow the outside system to access your application, these interfaces are your application service interfaces:

The implementation of your interface resides inside your application service layer, and the adapters use the service through its interface only. This is very much in line with the classical layered architecture, where the adapter is just another client that uses your application layer. The main difference is that the concept of ports helps you design better application interfaces since you have to think about what the clients of your interfaces will be and acknowledge that different clients may need different interfaces instead of going for a one-size-fits-all approach.
Things get more interesting when we look at a port that allows your application to access an external system through some adapter:

In this case, it is the adapter that implements the interface. The application service then interacts with the adapter through this interface. The interface either lives in your application service layer (a factory interface) or your domain model (a repository interface). This approach would not have been permitted in the traditional layered architecture as the interface would be declared in an upper layer (the "application layer" or the "domain layer") but implemented in a lower layer (the "infrastructure layer").
Please note that in both these approaches, the dependency arrows point toward the interface. The application always remains decoupled from the adapter, and the adapter always remains decoupled from the implementation of the application.
Let’s look at some code examples to make this even more concrete.
Example 1: A REST API
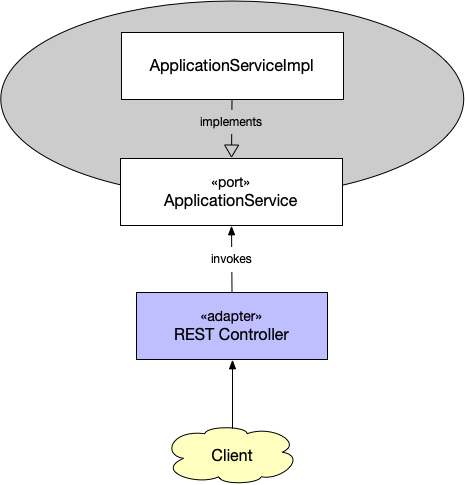
The port is an application service that is suitable to be exposed through REST. The REST controller acts as the adapter. Naturally, we are using a framework such as Spring or JAX-RS that provides both the servlet and mapping between POJOs (Plain Old Java Objects) and XML/JSON out-of-the-box. We only have to implement the REST controller, which will:
-
Take either raw XML/JSON or deserialized POJOs as input,
-
Invoke the application services,
-
Construct a response as either raw XML/JSON or as a POJO that the framework will serialize, and
-
Return the response to the client.
The clients, regardless of whether they are client-side web applications running in a browser or other systems running on their own servers, are not a part of this particular hexagonal system. The system also does not have to care about who the clients are as long as they conform to the protocol and technology that the port and adapter support.
Example 2: A server-side Vaadin UI
In the second example, we are going to look at a different type of adapter, namely a server-side Vaadin UI:
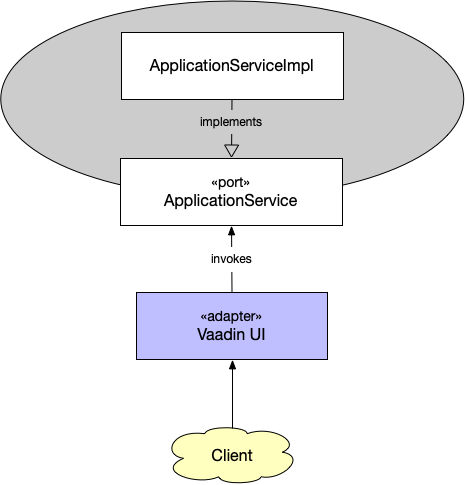
The port is an application service suitable for exposure through a web UI. The adapter is the Vaadin UI that translates incoming user actions into application service method calls and the output into HTML that can be rendered in the browser. Thinking of the user interface as just another adapter is an excellent way to keep business logic outside the user interface.
Example 3: Communicating with a relational database
In the third example, we are going to turn things around and look at an adapter that allows our system to call out to an external system, more specifically, a relational database:
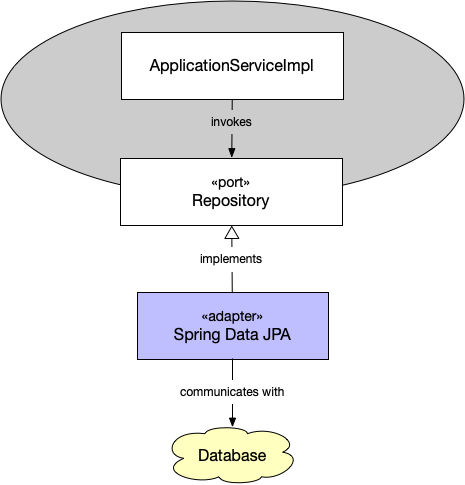
This time, because we are using Spring Data, the port is a repository interface from the domain model (if we didn’t use Spring Data, the port would probably be some kind of database gateway interface that provides access to repository implementations, transaction management, and so on).
The adapter is Spring Data JPA, so we don’t actually need to write it ourselves, only set it up correctly. It will automatically implement the interface using proxies when the application starts. The Spring container will take care of injecting the proxy into the application service that uses it.
Example 4: Communicating with an external system over REST
In the fourth and last example, we are going to look at an adapter that allows our system to call out to an external system over REST:
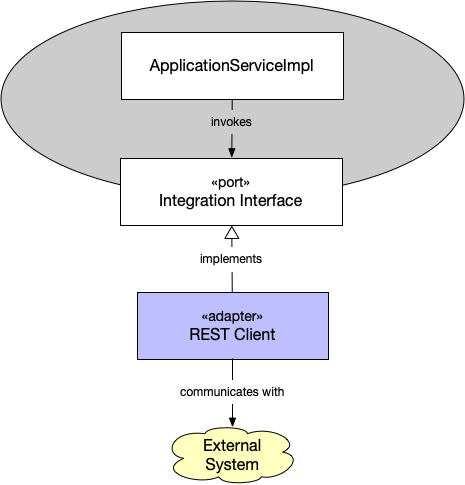
Since the application service has a need to reach out to the external system, it has declared an interface that it wants to use for this. You can think of this as the first part of an anti-corruption layer (go back and read the article about strategic DDD if you need a refresher on what that is).
The adapter then implements this interface, forming the second part of the anti-corruption layer. Like in the previous example, the adapter is injected into the application service using some kind of dependency injection, such as Spring. It then uses some internal HTTP client to make calls to the external system and translates the received responses into domain objects as the integration interface dictates.
Handling communication between multiple bounded contexts
So far, we have only looked at what the hexagonal architecture looks like when applied to a single bounded context. But what happens when you have multiple bounded contexts that need to communicate with each other?
Suppose the contexts are running on separate systems and communicating over a network. In that case, you can do something like this: Create a REST server adapter for the upstream system and a REST client adapter for the downstream system:
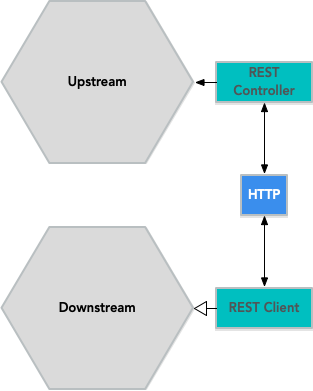
The mapping between the different contexts would take place in the downstream system’s adapter.
If the contexts are running as modules inside a single monolithic system, you can still use a similar architecture, but you only need a single adapter:

Since both contexts run inside the same virtual machine, we only need one adapter directly interacting with both contexts. The adapter implements the port interface of the downstream context and invokes the port of the upstream context. Any context mapping takes place inside the adapter.
Next steps
Ready to bring Domain-Driven Design and Hexagonal Architecture to life in your projects?
- Dive deeper: Explore our in-depth guides on Strategic Domain-Driven Design and Tactical Domain-Driven Design to master these principles.
- Get hands-on: Configure and download a real-world project at start.vaadin.com and see how these concepts work in practice.
Happy coding!