This is the first part of our in-depth series on Domain-Driven Design (DDD). Part two discusses tactical DDD, whereas, in part three, you'll learn how to apply DDD to working software using Java and Vaadin. Updated for 2024.
Domain-Driven Design (DDD) has been around since Eric Evans published his book about the subject in 2003. I myself came into contact with DDD some years ago when I joined a project that suffered from data consistency problems. Duplicates showed up in the database, some information was not saved at all, and you could run into optimistic locking errors anywhere and anytime. We managed to solve this by using the building blocks of tactical domain-driven design.
Since then, I have learned more about domain-driven design and tried to use it in my projects wherever appropriate. However, during the past years, when I have talked to other developers, many of them have heard about the term domain-driven design, but they do not know what it means.
In this article series, I am going to give a brief introduction to domain-driven design as I see and understand it. The content is very much based on the books Domain-Driven Design: Tackling Complexity in the Heart of Software by Eric Evans and Implementing Domain-Driven Design by Vaughn Vernon. However, I have tried to explain everything in my own words and also inject my own thoughts, opinions, and experiences.
You will not become an expert in domain-driven design by reading my article series, but I hope it inspires you to read more about it elsewhere. I also highly encourage you to read the books by Evans and Vernon.
Now let us start with the first subject, strategic domain-driven design.
What is a Domain?
If I look up the word domain in the Dictionary app on my MacBook, I get the following definition:
[A]n area of territory owned or controlled by a particular ruler or government…
a specified sphere of activity or knowledge…
In the case of domain-driven design, it is the second part of the definition that we are interested in. In this case, activity is whatever an organization does, and knowledge is how the organization does it. We are also going to add the environment in which the organization conducts its activities to the domain concept.
Subdomains
The domain concept is very broad and abstract. To make it more concrete and tangible, splitting it into smaller parts called subdomains makes sense. Finding these subdomains is not always easy, and if you get them wrong, you can run into trouble down the road when the pieces in your puzzle suddenly do not fit well together.
Before looking for subdomains, you should consider the subdomain categories. All subdomains can be divided into three categories:
-
Core domains
-
Supporting subdomains
-
Generic subdomains
Not only will these categories help you to find your subdomains, they will also help you to prioritize your development efforts.
A core domain makes an organization unique and different from others. An organization cannot succeed (or even exist) without being exceptionally good in its core domain. Because the core domain is so important, it should receive the highest priority, the biggest effort, and the best developers. You may only identify a single core domain for smaller domains, while larger domains may have more than one. You should be prepared to implement the features of the core domain from scratch.
A supporting subdomain is a subdomain that is necessary for the organization to succeed, but it does not fall into the core domain category. It is not generic either because it still requires some level of specialization for the organization in question. You may be able to start with an existing solution and tweak it or extend it to your specific needs.
A generic subdomain is a subdomain that does not contain anything special to the organization but is still needed for the overall solution to work. You can save a lot of time and work by trying to use off-the-shelf software for your generic subdomains. A typical example would be user identity management.
It is worth noting that the same subdomain can fall into different categories depending on what the organization does. For a company that specializes in identity management, identity management is a core domain. However, for a company that specializes in customer relations management, identity management is a generic subdomain.
Finally, it is worth pointing out that all subdomains are essential to the overall solution regardless of the category in which they fall. They do, however, require different amounts of effort and may also have different requirements of quality and completeness.
Example
Let’s say we are building an EMR (Electronic Medical Records) system for smaller clinics. We have identified the following subdomains:
-
Patient Records for managing patient medical records (personal information, medical history, etc.).
-
Lab for ordering lab tests and managing test results.
-
Scheduling for scheduling appointments.
-
File Archive for storing and managing files that are attached to the patient records (such as different documents, X-ray pictures, and scanned paper documents).
-
Identity Management for making sure the right people have access to the right information.
Now, how would we classify these subdomains? The most obvious ones are file archive and identity management, which are clearly generic subdomains. But what about the others? That depends on what is making this particular EMR system stand out among the others in the market.
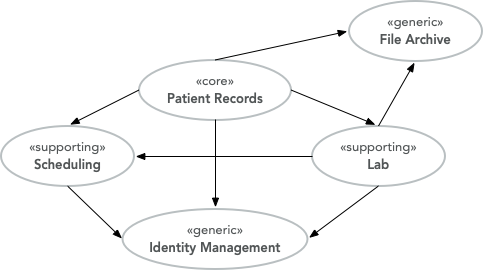
Since we are building an EMR system, it is pretty safe to assume that patient records are a core domain. Suppose we are going to take the market by making a system that makes all the clinics work more efficiently through clever and innovative scheduling. In that case, scheduling is probably also a core domain. Otherwise, it is a supporting subdomain, maybe built on top of some existing scheduling engine. The same reasoning can be applied to the lab subdomain: if a significant part of our business case is a seamless integration between patient records and the lab, then the lab is most likely a core domain. Otherwise, it is a supporting subdomain.
From Problems to Solutions
You sometimes find the domain referred to as the "problem domain". This comes from the fact that the domain defines problems that the software is going to solve (after all, there is a reason why the software is being made in the first place). Vaughn Vernon splits a domain into a problem and solution space. The problem space concentrates on what business problems we are trying to solve. The subdomains belong to this space.
The solution space concentrates on how the problems in the problem space are going to be solved. It is more concrete, more technical, and contains more details. So how are we going to transform our problems into solutions?
The Ubiquitous Language
To be able to create software for a domain, you need a way of describing the domain. Having a relational data model or something similar is not enough. You need to be able to describe things and their relations and the dynamics, such as events, processes, business invariants, how things change over time, and so on. You need to be able to discuss and reason about the domain with your fellow developers and domain experts. What you need is a ubiquitous language.
The ubiquitous language is a language that both domain experts and developers consistently use to describe and discuss the domain. Apart from the code itself, this language is the most important deliverable of a domain-driven design process. A big part of the language is domain terminology already being used by domain experts. Still, you may also need to invent new concepts and processes in cooperation with domain experts. Because of this, active participation from domain experts is absolutely essential for domain-driven design to succeed. Suppose the customer is not interested in putting in the time and effort to teach you their domain and help you create a ubiquitous language. In that case, you should either try to convince the customer to change their mind or pick another design method.
You can document the ubiquitous language in various ways. A good starting point is to create a glossary of terms. Business processes can be described graphically using, e.g., swimlane diagrams and flow charts. UML can be used to describe the relationship between things and state diagrams to describe how state changes as different things move through different processes. The subdomains are also a part of the ubiquitous language, and you may even need to define different "dialects" of the language for different subdomains. This embodiment of the ubiquitous language is the domain model, and it will eventually be transformed into working code. In other words, the domain model is not the same as a data model or a UML class diagram.
The ubiquitous language has a nice feature: it tells you whether you are on the right track or not. If you can easily explain a business concept or process using the language, it means you are on the right track. If you, on the other hand, struggle to explain something, you are most likely missing something from the language and, thereby, from your domain model. When this happens, you should grab a domain expert and go looking for the missing pieces. You may even stumble upon a revelation that turns your existing model completely upside-down and results in a far superior domain model than the one you had before.
Introducing Bounded Contexts
In a perfect world, only one ubiquitous language and one model would explain everything about a single domain. Unfortunately, this is not the case, save for very small and simple domains. Business processes may overlap or even conflict. The same word may mean different things or different words may mean the same thing in different contexts. Depending on how you view it, there may be (and often are) more than one way to solve a problem in the problem space.
Instead of trying to find the Big Unified Model, we accept the facts and introduce something called bounded contexts. A bounded context is a distinct part of the domain in which a particular subset or dialect of the ubiquitous language is consistent at all times. In other words, we are applying divide and conquer and splitting the domain model up into smaller, more or less independent models with clearly defined boundaries. Every bounded context has its name, which is a part of the ubiquitous language.
There is not necessarily a one-to-one mapping between bounded contexts and subdomains. Since a bounded context belongs to the solution space and a subdomain to the problem space, you should think about the bounded context as one alternative solution among many possible solutions. Thus a single subdomain can contain multiple bounded contexts. You may also find yourself in a situation where a single bounded context spans multiple subdomains. There is no rule against this, but it is an indication that you may need to rethink your subdomains or context boundaries.
Personally, I like to think about bounded contexts as separate systems (e.g., separate executable JARs or deployable WARs in the Java world). A perfect real-world example of this is micro-services, where each micro-service can be considered its own bounded context. However, this does not mean you have to implement all your bounded contexts as micro-services. A bounded context could also be a separate subsystem inside a single monolithic system.
Example
Let’s revisit the EMR system in the previous example and, more specifically, the patient records core domain. What kind of bounded contexts could we find there? Now I am no expert on healthcare software, so I will just make up some, but hopefully, you will get the idea.
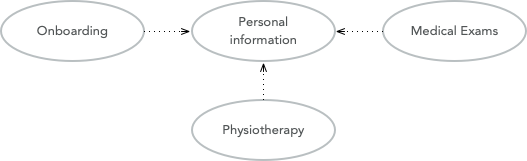
The system supports services for both doctor appointments and physiotherapy. In addition, there is a separate onboarding process for new patients where they are interviewed, photographed, and given an initial assessment. This leads to the following bounded contexts within the core domain:
-
Personal information for managing the patient’s personal information (name, address, financial information, medical background, etc.).
-
Onboarding for introducing new patients into the system.
-
Medical Exams used by doctors when examining and treating the patient.
-
Physiotherapy used by physiotherapists when examining and treating the patient.
In a very simple system, you probably would squeeze everything into a single context, but this EMR is more advanced and provides streamlined and optimized features for each type of service that is provided. However, we are still within the same core subdomain.
Relationships Between Contexts
In a non-trivial system, very few (if any) bounded contexts are entirely independent. Most contexts will have some kind of relationship with other contexts. Identifying these relationships is of importance not only technically (how will the systems technically communicate with each other) but also to how they are developed (how will the teams that develop the systems communicate with each other).
The simplest way to identify relationships between bounded contexts is to classify the contexts as upstream contexts and downstream contexts. Think of the contexts as cities next to a river. The cities upstream dump stuff into the river, which reaches the cities downstream. Some of the stuff is essential to the downstream cities, and so they retrieve it from the river. Other stuff is harmful and can do direct damage to the downstream cities ("sh*t rolls downhill").
Being upstream or downstream has its pros and cons. An upstream context does not depend on any other context, making it free to evolve in any direction. However, the consequences of any changes may be severe in downstream contexts, and this may, in turn, impose restrictions on the upstream context. A downstream context is restricted by its dependency on an upstream context. Still, it does not need to worry about breaking other contexts further downstream, which in a way, gives the developers of the downstream context freer hands than the developers of the upstream context.
You can describe the relationships graphically using a dependency diagram where arrows point from the downstream contexts to the upstream contexts or using the U and D roles.
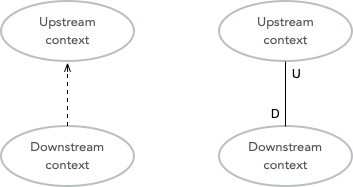
Finally, keep in mind that a context can be both an upstream context and a downstream context at the same time, depending on where you stand.
Context Maps and Integration Patterns
Once we know what our contexts are and how they are related, we have to decide how to integrate them. This involves several important questions:
-
Where are the context boundaries?
-
How are the contexts going to communicate technically?
-
How are we going to map between the contexts' domain models (i.e., how are we translating from one ubiquitous language to another)?
-
How are we going to guard against unwanted or problematic changes occurring upstream?
-
How are we going to avoid causing trouble for downstream contexts?
The answers to these questions will be compiled into a context map. The context map can be documented graphically like this:

To make creating the context map easier, a set of ready-made integration patterns work for most use cases. Depending on which integration pattern you pick, you may have to add additional information to the context map to make it really useful.
Partnership
The teams of both contexts cooperate. The interfaces - whatever they are - evolve to accommodate both contexts' development needs. Interdependent features are properly planned and scheduled so that they cause as little harm as possible to both teams.
Shared Kernel
Both contexts share a common code base which is the kernel. The kernel can be modified by any of the teams, but not without consulting the other team first. Continuous integration (with automatic testing) is required to ensure no unintended side effects are introduced. The shared kernel should be kept as small as possible to keep things as simple as possible. If a lot of model code ends up in the shared kernel, it may be a sign that the contexts should, in fact, be merged into one big context.
Customer-Supplier
The contexts are in an upstream-downstream relationship, and this relationship is formalized such that the upstream team is the supplier and the downstream team is the customer. Thus, even though both teams can work more or less independently on their systems, the upstream team (supplier) is required to take the downstream team’s (customer) needs into account.
Conformist
The contexts are in an upstream-downstream relationship. However, the upstream team has no motivation to accommodate the downstream team’s needs (it may be ordered as a service from a larger supplier, for example). The downstream team decides to conform to the model of the upstream team, whatever it happens to be.
Anticorruption Layer
The contexts are in an upstream-downstream relationship, and the upstream team does not care about the downstream team’s needs. However, instead of conforming to the upstream model, the downstream team decides to create an abstraction layer that protects the downstream context from changes in the upstream context. This anti-corruption layer lets the downstream teamwork with a domain model that suits their needs the most while still integrating with the upstream context. The anticorruption layer must also change when the upstream context changes, but the rest of the downstream context can remain unchanged. It may be a good idea to combine this strategy with continuous integration, where automated tests are used to detect changes in the upstream interface.
Open Host Service
Access to a system is provided by clearly defined services using a clearly defined protocol. The protocol is open so that anybody who needs to can integrate with the system. Web services and micro-services are good examples of this integration pattern. This pattern is different from the others in that it does not care about the relationship between the contexts and the teams that develop them. You may end up combining the open host service pattern with any of the other patterns.
The key when using this pattern is to keep the protocol simple and stable. Most of the system's clients should be able to get what they need from this protocol. Create special integration points for the remaining exceptional cases.
Published Language
I find this integration pattern the most difficult to explain adequately. The way I look at it, the published language is the closest relative to the open host service and is often used together with that integration pattern. A documented language (for example, based on XML) is used for the input and output of the system. There is no need to use a particular library or a particular implementation of a spec as long as you conform to the published language. Real-world examples of published languages are MathML for representing mathematical formulas and GML for representing geographical features in geographical information systems.
Please note that you do not necessarily need to use web services together with a published language. You could also have a setup where a file is dropped into a directory and processed by a batch job that stores the output in another file.
Separate Ways
This integration pattern is special in that it does not perform any integration at all. Still, it is a critical pattern to keep in the toolbox and may end up saving a lot of money and time. When the benefit of the integration between two contexts is no longer worth the effort, it is better to cut the contexts loose from each other and let them evolve independently. This could be because the systems have simply evolved to a point where they are no longer related. The (few) services provided by the upstream context that the downstream context actually used are re-implemented inside the downstream context.
Why is Strategic Domain-Driven Design Important?
I believe strategic domain-driven design was initially meant for larger projects. Still, I think you can benefit from it also in smaller projects - even if you end up not using any other parts of DDD in the project.
For me personally, the major takeaways from strategic domain-driven design are the following:
-
It introduces boundaries. Scope creep is a constant factor in all of my hobby projects. Eventually, they become more exhaustive than fun to work on or entirely unrealistic for finishing alone. When working on customer projects, I have to work hard not to cause technical scope creep by overthinking or overengineering things. Boundaries - wherever they are - help me to divide the project into smaller parts and focus on the right ones at the right time.
-
I do not need to find a super-model that works in all cases. It recognizes that there are often many smaller models in more or less clearly defined contexts in the real world. Instead of breaking these models, it embraces them.
-
It helps you think about the value your system will bring and where you should put the most of your efforts to get the biggest value. I have personal experience from projects where correctly identifying and then concentrating on the core domain would have made an enormous difference. Unfortunately, I had not heard about strategic DDD, and time and money were wasted.
I also know myself well enough to identify risks with this approach: finding subdomains and bounded contexts for the sake of finding subdomains and bounded contexts. When I learn something new that I like, I very much want to try it out in the real world. That may sometimes mean I go looking for things that are not there. I suggest always starting with one core domain and one bounded context. I do the domain modeling carefully. Additional subdomains and bounded contexts will eventually reveal themselves if they exist.
Next up: Tactical Domain-Driven Design
In part two of the series, we are going to look at the tactical domain-driven design. You will learn about the building blocks you can use to transform your bounded contexts into implementable designs. These building blocks will also aid you in creating the domain model and the ubiquitous language.
Or, if you want to learn how to apply DDD to working software using Java and Vaadin, jump to part three.
New to Vaadin? Configure and download a project to create your own Vaadin app on start.vaadin.com!