On my personal blog, I wrote some time ago a lengthy piece listing the reasons why I love Vaadin.
However, a technology stack has both pros and cons. It fits some contexts better than some others. Vaadin is like any other stack in that regard: because it stores state on the server, it’s not a good fit when there are a high number of concurrent clients. To be more precise, "high" starts around 10k, and "concurrent" is… concurrent. I know only very few apps with that level of concurrency. But storing state on the server-side has a definite downside.
In this post, I’d like to describe the context, walk through this issue, and propose a solution to it.
 Clusters, nodes, and Load Balancers
Clusters, nodes, and Load Balancers
Because of low costs, contemporary architectures use clustered middleware nodes behind a Load Balancer. From a bird’s eye view, here’s how a LB works. The LB keeps a list of its nodes. When it receives a request, it forwards it to a node according to a dedicated policy: round-robbin, node with the smallest number of ongoing requests, etc.
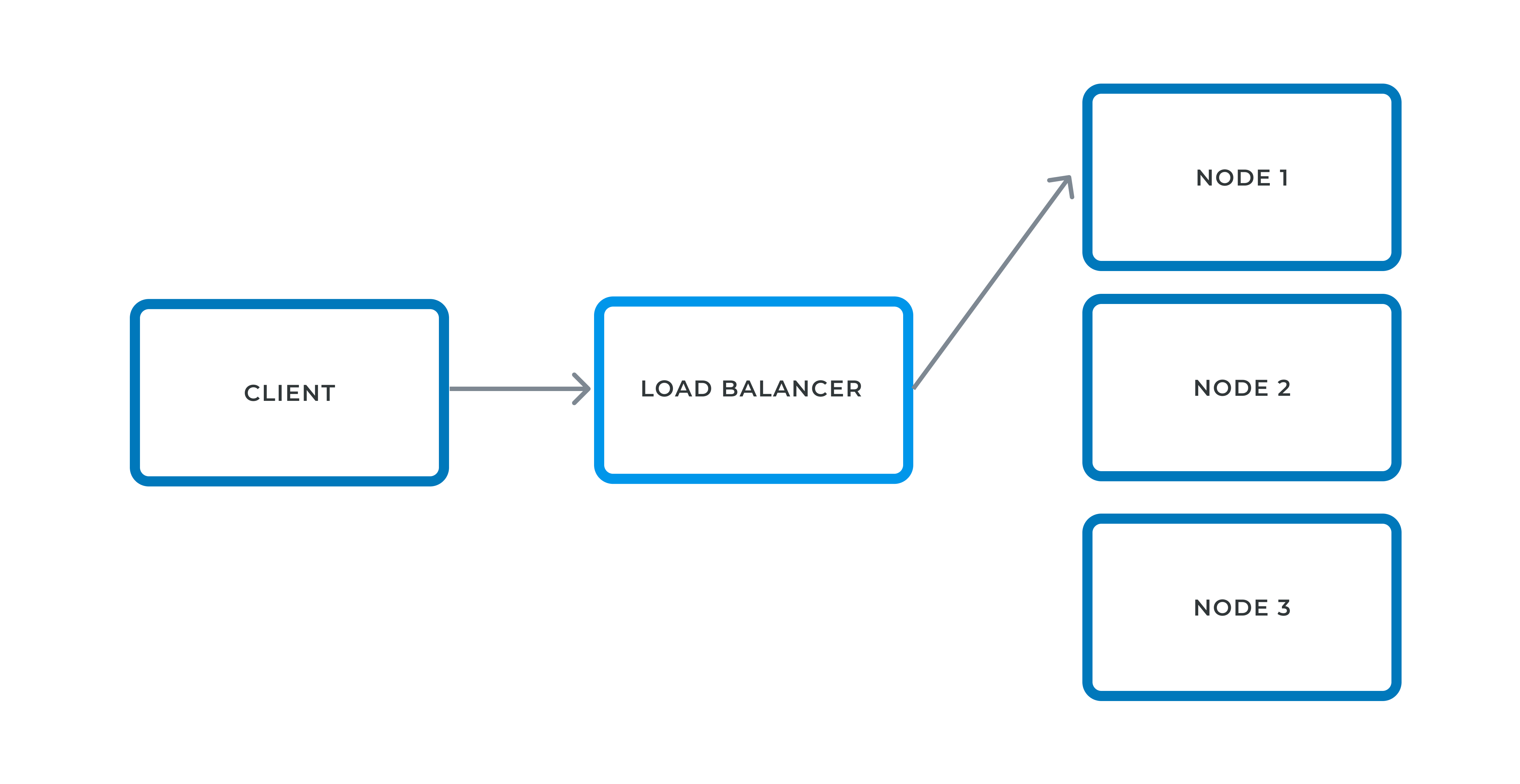
When a node quits, it unregisters from the LB; when a new node joins, it registers itself to the LB. Also, nodes will fail: it’s not a matter of if, but a matter of when. To handle this failure, production-grade LBs send health checks to nodes at regular intervals. When a node fails to respond, he’s removed from the list.
Sticky sessions
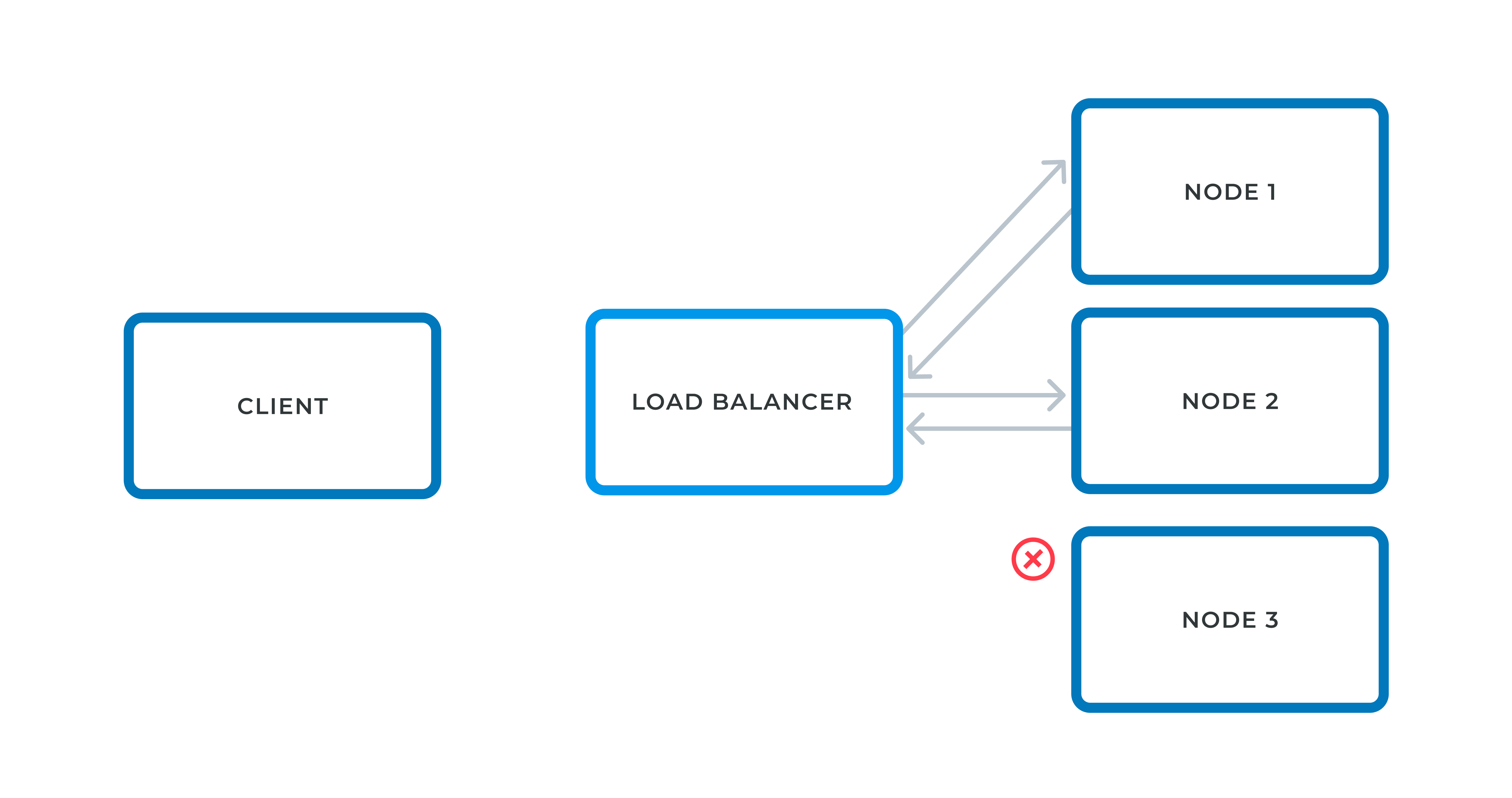
Now, let’s put that understanding in the context of stateless applications. In such a context, any node can handle the request. Regarding stateful applications this is not the case. The LB might forward a request to a node that is not the one that served the previous one. Because the applications stores the state server-side, it’s as if the state starts from scratch from the client point-of-view.
To cope with that limitation, the LB needs to be smart. It keeps a list of clients, and which node they were forwarded to. To achieve that, it cannot rely on HTTP because it’s stateless.
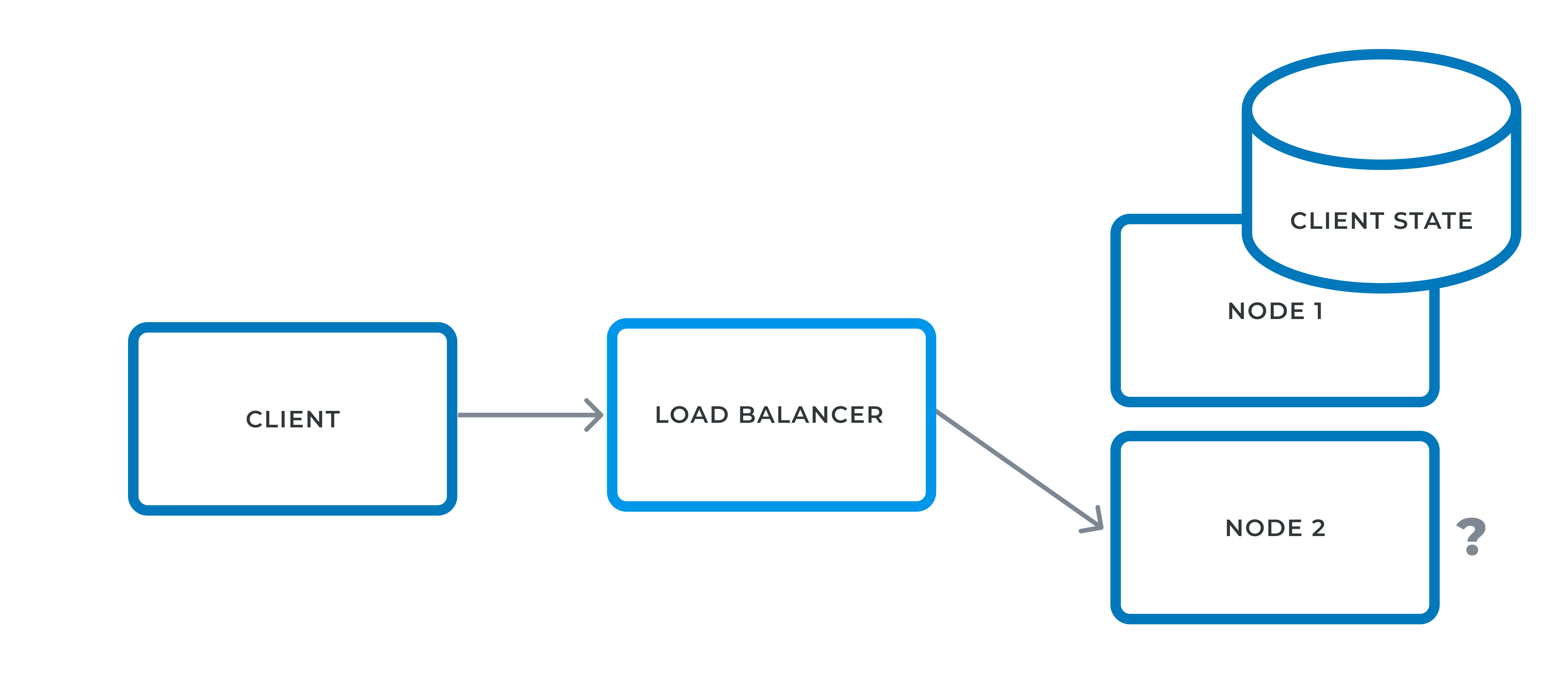
However, most technology stacks do have the concept of a session: an in-memory location related specific to a client. The reason for that is that state storage is not only relevant to Vaadin, but a very general concern. For example, in e-commerce applications, cart data is not usually stored in the database for performance reasons, but on the application node i.e. in-memory.
The process is as follow: one the first request, the client is forwarded to a node accorded to the LB policy. When the response is returned by the node, it contains a stack-specific cookie e.g. JSESSIONID for Java EE, PHPSESSID for PHP, and ASPSESSIONID for ASP. At this time, the cookie is associated to the node in the LB. The next request from the same client-side session will contain the same cookie, and the LB knows to which node to forward it to.
Session replication
The previous approach works very well…until a node fails. While the client subsequent requests will be forwarded to other nodes, the state stored on the failed node will be lost. In some cases, it’s acceptable to lose state. In some others, it’s not, such as the aforementioned e-commerce cart.
A straightforward solution is to move data outside the application nodes to a dedicated database. For each request that requires stored data, the database needs to be queried and data must be unserialized. Those extra steps have an impact on the overal performance of the application.
Another solution is to copy session data to other nodes. This way, when the node fails, the client will be forwarded to another node that will also contain the required data. Replication needs to be reliable, thus automated.
There are a couple of available solutions: when using Spring, the Spring Session library allows to transparently manage this replication. However, when not, one needs to directly rely on an implementation.
Hazelcast IMDG
In the rest of this post, I’ll be using Hazelcast In-Memory Data Grid.
In short, Hazelcast IMDG offers a bunch of distributed data structures. Those structures offer an API very similar to the ones that come with the JDK. However, Hazelcast manages the replication and sharding of data across cluster nodes. By default, nodes will multicast to find other nodes and form a cluster.
There are two to deployment alternatives:
- Embedded mode
-
Just add the Hazelcast JAR to your webapp, and start the instance from within it. This is the easiest option by far. Additionally, at least one node will have the data at hand.
- Client-server mode
-
Deploy dedicated Hazelcast nodes. Application instances will be client of those nodes. In this case, application don’t need to be written in Java, as several client libraries are available (C++, C#, Python, Go, Node.js).
One of the available data structures that Hazelcast provides is the associative array (or dictionary, or hash map). In that regard, a session could be stored (and retrieved) through its id.
There are several integrations available:
-
Finally, if none of the above fits your context, it’s always possible to use the
Filter-based implementation
A demo application
The demo is simple, but should highlight how things work.
The application is a simple task application. A Task has an id, a label, a status, and a created timestamp.
public class Task implements Serializable {
private final UUID id;
private final String label;
private final LocalDateTime created;
private boolean done;
public Task(String label) {
this.label = label;
this.id = UUID.randomUUID(); (1)
this.created = LocalDateTime.now(); (2)
}
// Getters and setters
}-
UUID is set randomly
-
The creation timestamp is automatically set from the system clock
Tasks are displayed in a Vaadin Grid.
public class TaskGrid extends Grid<Task> {
private final List<Task> tasks = new ArrayList<>();
public TaskGrid() {
super(Task.class, false);
configureDataProvider();
configureCellRenderers();
configureHeaders();
}
// ...
}The grid header shows a text field and an Add button.
public class TaskGrid extends Grid<Task> {
// ...
private void configureHeaders() {
HeaderRow addTaskRow = appendHeaderRow();
TextField labelField = new TextField();
addTaskRow.getCell(labelColumn()).setComponent(labelField);
Button addButton = new Button("Add");
addTaskRow.getCell(doneColumn()).setComponent(addButton);
addButton.addClickListener(addTask(labelField));
// ...
}
// ...
}When the latter is clicked, a new task with the label copied from the content of the text field is created, and the text field is cleared.
public class TaskGrid extends Grid<Task> {
// ...
private ComponentEventListener<ClickEvent<Button>> addTask(TextField field) {
return event -> {
Task task = new Task(field.getValue());
field.clear();
tasks.add(task);
getDataProvider().refreshAll();
};
}
// ...
}
We will store the Grid itself in the session. Hence, every time the user changes the state of the grid, the latter needs to be saved. In this sample app, there are two ways to change the state:
-
Add a new task
-
Change the done status of a task
public class TaskGrid extends Grid<Task> {
// ...
private ComponentEventListener<ClickEvent<Button>> addTask(TextField field) {
return event -> {
// ...
saveState(); (1)
};
}
private void configureCellRenderers() {
// ...
addComponentColumn(item -> {
Checkbox cb = new Checkbox(item.isDone());
cb.addClickListener(event -> item.setDone(cb.getValue()));
saveState(); (2)
return cb;
});
// ...
}
private void saveState() {
VaadinSession.getCurrent().getSession().setAttribute("grids", this); (3)
}
}-
Save the state when a new
Taskis added -
Save the state when the
doneattribute of aTaskis changed -
Get the underlying
Sessionobject, and overwrite itsgridsattribute
When the view is instantiated, it needs to check if there’s a Grid object in session. If there’s one, it should use it; if not, it should create a new one.
@Route
public class MainView extends VerticalLayout {
public MainView() {
add(tasksGrid());
}
private Component tasksGrid() {
Object object = VaadinSession.getCurrent().getSession().getAttribute("grids"); (1)
TaskGrid grid = object == null ? new TaskGrid() : (TaskGrid) object; (2)
grid.getElement().removeFromTree(); (3)
return grid;
}
}-
Get the
gridsattribute from the underlying session -
Use it or create a new
Grid -
If the
Gridcomes from an existing session, it belongs to a components hierarchy. It needs to be detached from the existing tree, before being attached to a new layout.
Infrastructure setup
The infrastructure consists of the following:
-
Two Tomcat nodes that serve the Vaadin application
-
One front-end Load-Balancer configured with sticky sessions that forwards requests to the above
You might have noticed that that application itself is completely oblivious to session replication. That’s a good thing, as it should be the concern of the application server. In that regard, both Tomcat instances are configured with Hazelcast session replication. Steps are as follow:
-
Add the Hazelcast JAR to the
libfolder -
Configure Hazelcast via the
hazelcast.xmlfile, and put the latter in theconffolder -
Add Hazelcast Session manager to the context:
conf/context.xml<Context>
<Manager className="com.hazelcast.session.HazelcastSessionManager" deferredWrite="false"/>
</Context> -
Configure the server to start Hazelcast on startup, with the relevant configuration:
conf/server.xml<Server port="8005" shutdown="SHUTDOWN">
<!--- // --->
<Listener className="com.hazelcast.session.P2PLifecycleListener" configLocation="conf/hazelcast.xml"/>
<!--- // --->
</Server>
At this point, a new Hazelcast instance will be created when Tomcat starts. They will multicast, find each other, and form a cluster. Every time a change is made in the session on a node, like setting the Grid object, the session’s content will be stored in Hazelcast on this mode. The content will be replicated on the other node.
Testing the demo
The objective is to interact with the application, and kill the Tomcat node that the session has been created on. On the next request, the browser should be forwarded to the other node, with all session data intact.
Docker is required to test the demo. The previous infrastructure setup has already been described in a docker-compose file.
| The local Docker daemon needs to be up during the following |
-
Open a terminal window in the project’s root directory
-
It’s necessary to build the Tomcat container with the webapp:
docker build -t hazelcast/vaadin-session . -
It’s now possible to launch the whole infrastructure:
docker-compose up -
Point your favorite browser to <http://localhost/>. It will display the application. Add tasks, and mark some of them as done.
Notice the node you’ve been forwarded to in the upper left corner. To stop this node, open a new terminal window in the root directory and type:
docker-compose stop node1 (1)-
Replace
node1bynode2if the node the session has been stuck to isnode2
-
-
Add a new task. Enjoy!
At the moment, there’s a
Filterthat needs to mark the Vaadin session as "dirty" in order for Hazelcast to pick the changes. The Vaadin team is considering theFilterto be integrated with the framework in an upcoming release.
Conclusion
In this post, we have looked at the way sessions are managed: in-memory on the node. To keep accessing the same data, we need to configure sticky sessions on the load balancer. However, when the node fails, we lose the session data as well.
With the help of Hazelcast, we can transparently enable session replication. In that case, even when a node fails, the user is forwarded to another node that happens to have all the session data available.
With sticky sessions and session replication, you have the best of both worlds: performance when the node is working, and reliability when it fails.
Hazelcast allows to work as if on a single node, and make session replication an infrastructure concern. Together with Vaadin, this enables developers to design truly awesome applications.
Source code on GitHub.