
Relational databases, RDBMSes, are the de-facto persistency solution for business apps. RDBMSes excel at large amounts of simple, not particularly complex data. Historically, each table is a structure of rows on disk. When you do a join, it’s an optimization on disk to help locate a pointer to follow. So, the relationships (JOINs, which are just pointer dereferences) are an optimization for the computer, not for the benefit of the data model.
All the work you do to set up indexes and foreign keys is just to give the database ways to travel without doing full page scans. This is also why redefining relationships is so hard, because it means shuffling around indexes. This discourages traversing the relationships freely.
What other options could we use to persist our domain data? Various NoSQL/”big data” storages have been popular lately, but most of them focus on scalability and handling a huge amount of data, rather than managing interesting highly interconnected data structures.
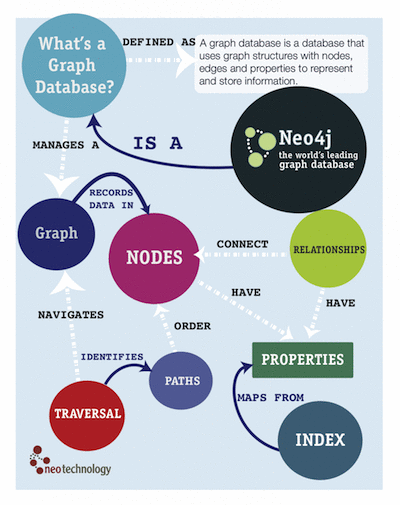
Graph databases, like Neo4j, differ from other databases in that entity relations are implemented with pointers, instead of foreign keys and indexes. This makes certain types of “join queries” magnitudes faster. Graph databases are thus a better fit for cases where associations between entities are complex in both data model and queries. Neo4j is schema-optional, schema won’t disturb you as you’re developing your data model.
Neo4j is implemented in Java and Scala and can be embedded in your application’s JVM or as a standalone server. The latter is handy in case you want to distribute your computation and interact from non-JVM languages via the http-API. Horizontal scaling for fail-over and reads is available in the commercial edition, so you can easily add new servers to your DB in case your app starts booming.
OGM - OMG yet another TLA!
When you connect to your database, for example using the Console (neo4j console, then open http://localhost:7474/), you’ll see nodes and relationships, not tables, columns, and rows. Nodes and relationships can store properties for details. You can use the Cypher language to manipulate and query the data. To keep things as simple as possible, you might use Spring Data repositories and Cypher, together.
You can map objects to records in your graph database using an Object to Graph Mapping (OGM) library, like Spring Data Neo4j.
The OGM part has actually two implementations. The older, “advanced method”, uses AspectJ to weave entities to dynamically fetch related nodes and update underlying graph DB. In case this is not an option for you, you can also use the newer “simple usage mode”, which copies the necessary information from the graph into your domain objects. Like with JPA, you will use some simple annotations to give hints for the object mapping library. The following code snippet shows essential parts of an annotated entity from an example application.
@NodeEntity
public class Person {
@GraphId
private Long id;
private String name;
@RelatedTo(type = "PROJECT", direction = Direction.OUTGOING)
@Fetch
public Set<Project> projects;
It’s easy to get quickly started with Spring Data. You can use repositories to handle basic CRUD requirements, and define custom finder methods that - based on naming convention - handle more complex graph queries for you. You can also override the query generated by explicitly providing a @Query annotation. Here’s an example PersonRepository:
public interface PersonRepository extends GraphRepository<Person> {
// this query is autogenerated by convention
Iterable<Person> findByProjectsName(String name);
@Query("YOUR CUSTOM CYPHER QUERY")
Iterable<Person> getByCustomQuery(Person parameter);
Neo4j supports transactions like relational databases due to its fine-grained data model. You can handle them manually, but when building on top of Spring Data, you are almost always better off by delegating that to Spring. Just enable transaction management in your configuration and annotate methods or service classes with @Transactional.
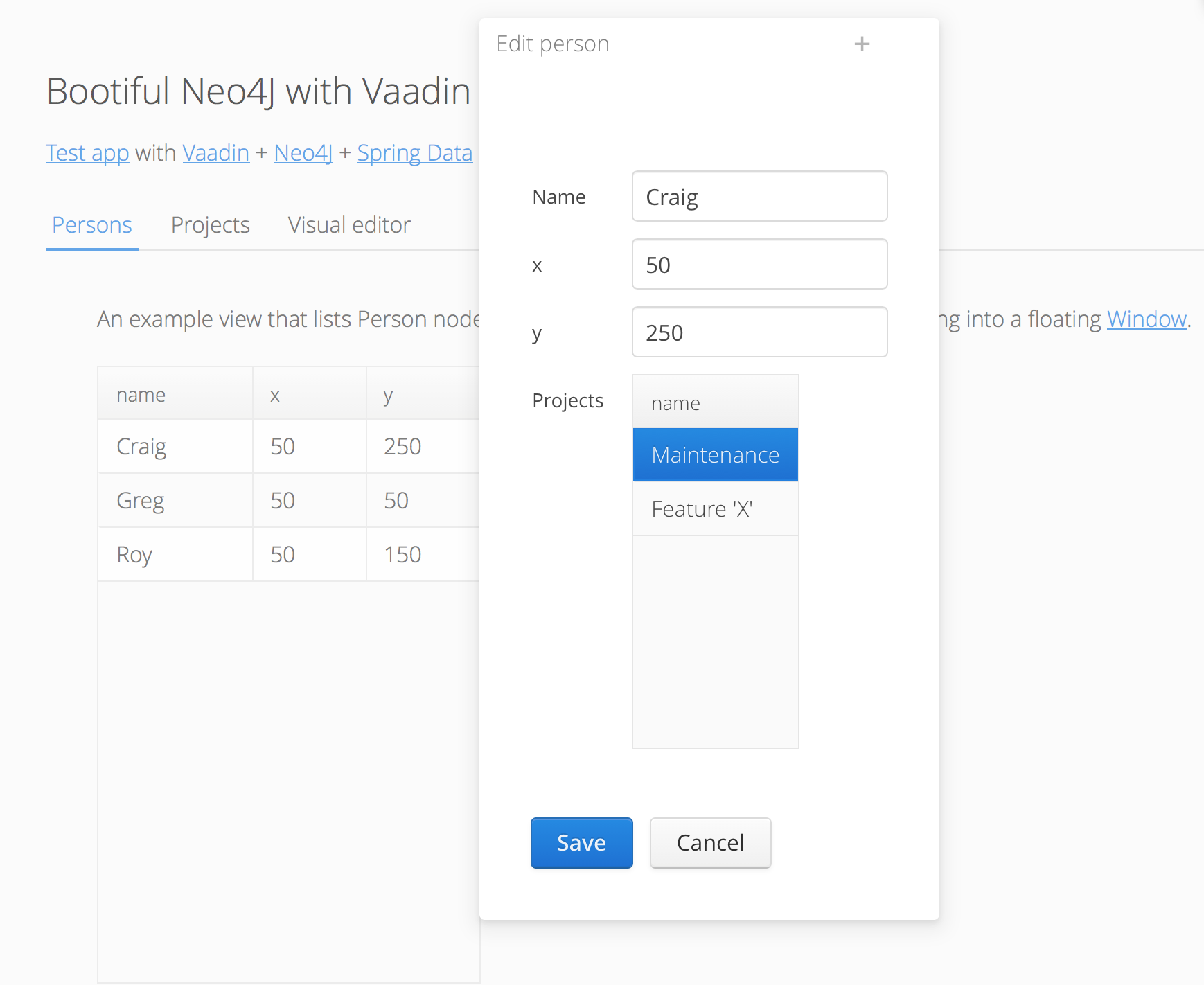
Screenshot of the Vaadin + Spring Data Neo4j demo app
In case you want to use your graph database in a solution that even your grandma can use, you’ll naturally need a graphical UI for your application. As a server-side library, Vaadin makes integration to Neo4j repositories extremely simple. Using the Vaadin4Spring library, a recently started project by Petter Holmström and Josh Long, one can just inject service classes directly to Vaadin UI classes and handle the data like with any simple POJOs.
As a proof of concept we have created a simple demo application using two entity types, Person and Project. There is also an experimental visual mode, to edit the whole graph using AlloYUI Diagram Builder.
Based on the experience from the example, we can recommend to evaluate the combination of Neo4j, Spring Data and Vaadin. It seems like a natural fit for applications with a complex domain model that has high probability for changes, but which still need a scalable and reliable persistence solution - which is most usually the case for Vaadin applications.
Check out the Vaadin-Neo4j example project
 Josh Long is the Spring Developer Advocate. Josh is the lead author on several books for Apress and O’Reilly, as well as the host for Pearson’s “Spring” and “REST Development with Spring” Livelessons video series and a committer on several Spring projects and the Activiti BPMN framework. When he’s not hacking on code, he can be found at the local Java User Group or at the local coffee shop. Josh likes solutions that push the boundaries of the technologies that enable them. Josh’s interests include big-data, mobile, REST, NoSQL and integration. He blogs on the Spring blog and on his personal blog. You can fllow Josh on Twitter - @starbuxman
Josh Long is the Spring Developer Advocate. Josh is the lead author on several books for Apress and O’Reilly, as well as the host for Pearson’s “Spring” and “REST Development with Spring” Livelessons video series and a committer on several Spring projects and the Activiti BPMN framework. When he’s not hacking on code, he can be found at the local Java User Group or at the local coffee shop. Josh likes solutions that push the boundaries of the technologies that enable them. Josh’s interests include big-data, mobile, REST, NoSQL and integration. He blogs on the Spring blog and on his personal blog. You can fllow Josh on Twitter - @starbuxman
 Michael Hunger has been passionate about software development for a very long time. For the last few years he has been working with Neo Technology on the Neo4j graph database. As the project lead of Spring Data Neo4j he helped developing the idea to become a convenient and complete solution for object graph mapping. Michael now takes care of the Neo4j developer community. As a developer Michael loves to work with many aspects of programming languages, learning new things every day, participating in exciting and ambitious open source projects and contributing and writing software related books and articles. You can follow Michael on Twitter - @mesirii
Michael Hunger has been passionate about software development for a very long time. For the last few years he has been working with Neo Technology on the Neo4j graph database. As the project lead of Spring Data Neo4j he helped developing the idea to become a convenient and complete solution for object graph mapping. Michael now takes care of the Neo4j developer community. As a developer Michael loves to work with many aspects of programming languages, learning new things every day, participating in exciting and ambitious open source projects and contributing and writing software related books and articles. You can follow Michael on Twitter - @mesirii