

Grid
A powerful datagrid component with lazy-loading, filters, sorting, drag & drop, frozen columns and inline editing.
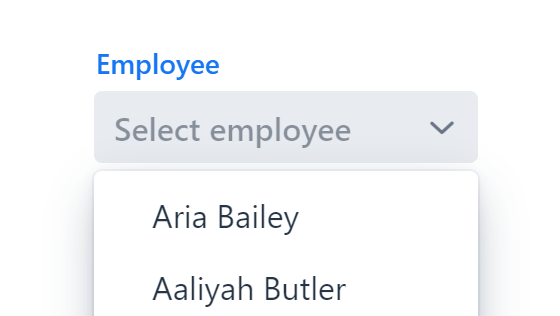
Combo Box
A filterable drop-down field with lazy loading and customizable item rendering.

Charts
A library of 29 different types of feature-rich, interactive charts for data visualization.
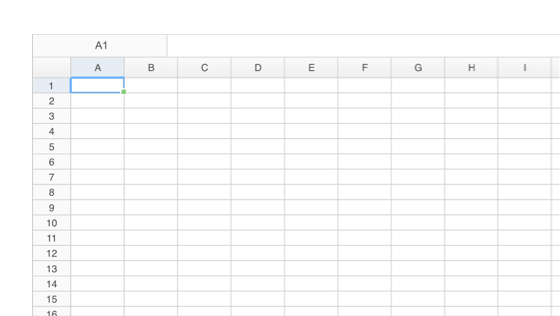
Spreadsheet
An interactive spreadsheet component for displaying and modifying the contents of an Excel file within an app.