Introduction
If I had to guess, I would say that most Vaadin applications are self-contained, with the UI and the business logic packaged inside the same application archive and running inside the same Java virtual machine (VM). However, there are cases where it makes more sense to separate the UI and the backend into two separate Java applications. The applications will obviously need some way of communicating with each other and in this article, I am going to share some thoughts about doing this with REST.
In my opinion, the greatest strength but also the greatest weakness of REST is that it is essentially just HTTP. You get to decide what the messages look like, how the URLs are structured, how parameters are passed, how errors are handled, etc. On the one hand, you can build a protocol that is optimized for your particular application. On the other hand, you have to be really disciplined to keep your protocol consistent and not turn it into an incoherent mess. This is especially important if there are more than one developer working on the REST API.
Setting up the project
When setting up a project for a two-tiered application with a separate backend and frontend, the first setup that comes to mind could look something like this:

The backend and frontend have their own modules, but there is a shared module that contains the data transfer objects (DTO) that are used to transfer information over REST. I have used this model myself in several projects and have now started to think that this is actually not a good solution, especially if the DTOs are serialized to XML or JSON.
Having a shared module for the DTO unnecessarily couples the frontend and the backend to each other. This is especially troublesome if there are separate teams working on the frontend and the backend. The backend team can make changes to the DTO module without knowing how those changes will affect the frontend application and vice versa. The risk of accidentally - or intentionally - sneaking stuff into the shared module that really should not be there is also higher. Finally, this imposes limits on how you actually implement the DTOs. It might make more sense to implement the DTOs in different ways in the frontend and the backend.
Because of this, it is now my belief that if a platform agnostic remoting protocol such as REST is to be used, it is better to do a little bit of copying and keeping the backend and the frontend modules completely separate, than to have a shared library:

Choosing a message format
REST does not require you to use a particular message format. You can even use Java serialization or some other binary protocol if you want to. However, the most common alternatives are JSON and XML. Both have their pros and cons.
The advantage with using XML is that you can define all your DTOs in an XML Schema. This schema can then be used to generate Java classes wherever they are needed (both on the backend and the frontend). You also get the message format documentation “for free” and you do not need to rely on any third-party libraries or tools since Java has good built-in support for XML.
There are a few drawbacks as well. Maintaining the schema requires some work and the generated classes are the same on both the frontend and the backend. If you care about the size of the messages, JSON is more compact than XML since it does not require ending tags.
If you are designing a REST API for a frontend that is implemented in JavaScript (e.g. Polymer and Vaadin Elements), then JSON is your number one choice. This is also the alternative I would recommend if you want to code your DTOs yourself as opposed to auto-generating them. There are different libraries available for doing the actual conversion to and from JSON (personally, I prefer Jackson).
The drawback with using JSON is that you have to maintain the message format documentation and the code separately. There is a JSON Schema standard coming, but it is still a draft.
Picking HTTP methods
Picking the correct HTTP methods to use for simple CRUD operations is easy:
-
POST for Creating new entities
-
GET for Retrieving existing entities
-
PUT for Updating existing entities
-
DELETE for Deleting existing entities
However, in most non-trivial applications, you want to be able to do more than just CRUD, otherwise you are moving the business logic to the frontend or even into the heads of the users (which does not always need to be a bad thing, as long as it is intentional).
There are tens of different HTTP methods in addition to the four well-known methods mentioned before. Unfortunately, very few of them are easily usable in modern Java REST frameworks, such as JAX-RS and Spring. Therefore we are going to need to do some compromises and misuse some of the existing methods.
All HTTP methods can be classified according to two properties: safe and unsafe methods, and idempotent and non-idempotent methods.
A safe method is guaranteed not to break anything if you call it. GET is such a method, since you should never be able to change the state of the system through a GET operation. POST, PUT and DELETE on the other hand are unsafe methods, since they can alter the state of the system.
An idempotent method is guaranteed to have the same end result regardless of how many times you call it with the same parameters (provided that nobody else has altered the state of the system between calls). GET, PUT and DELETE are idempotent methods whereas POST is not.
So what rules can we break when we need to pick a method for invoking business operations that do not fall into the CRUD category? Making a safe operation unsafe is not acceptable but vice versa is OK. This also applies to idempotency. This leads to the following rules-of-thumb:
-
If you need to perform an advanced query where the query parameters are in the request body, use a PUT. This makes an unsafe operation safe and it continues to be idempotent. You cannot use a GET here because GET requests do not have bodies.
-
If you need to perform a business operation that changes the state of the system, you have to consider the idempotency: if calling the same operation twice in a row with the exact same input parameters will have different end results or side effects, you should use a POST. Otherwise, you should use a PUT.
Designing the structure of your REST resources
Getting your resource structure right and using it consistently is very important in order to keep your REST API extendable and understandable. In one end of the spectrum, you may have a message bus inspired approach where all messages are POSTed to a single resource. The message contents dictate what to do with them.
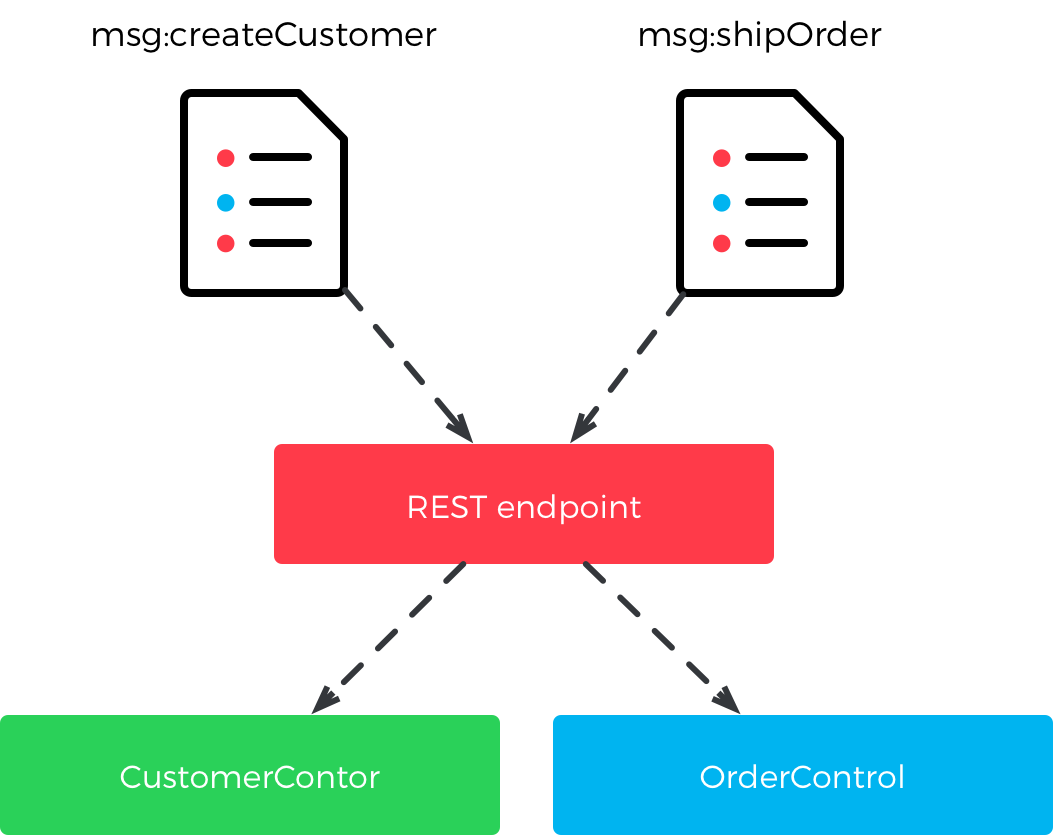
In the other end of the spectrum, your entire data model is available as a resource tree where even individual entity properties can be addressed.
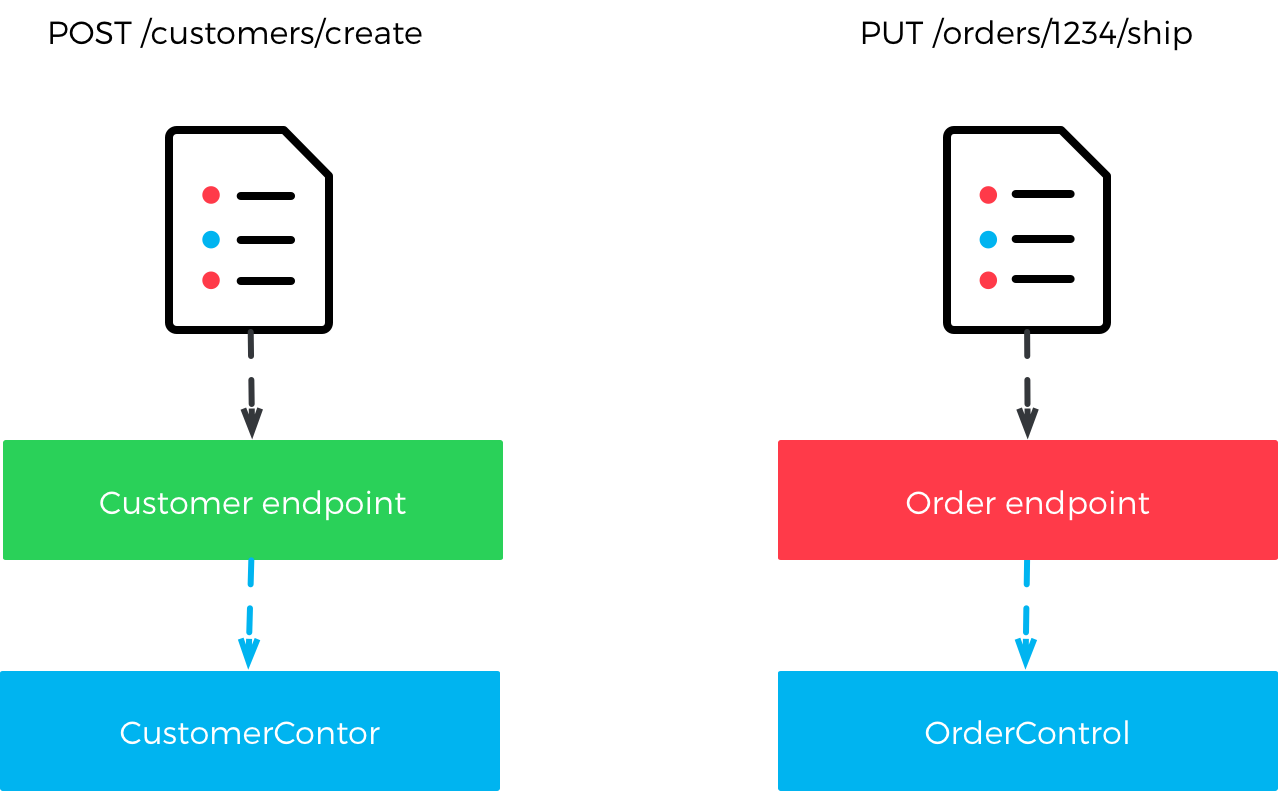
Most applications probably fall somewhere in the middle.
Versioning your API is a good idea from day one since you may end up supporting multiple versions of your REST API at the same time in the future. Instead of having the version information embedded into the HTTP request itself (for example as a header or even inside the message body), it is easier to just have it in the URL (for example /api/1.0/customers and /api/2.0/customers).
Since REST is a stateless protocol, I like to keep as much contextual information as possible in the URL path itself. Let us take an example to illustrate. In a multi-tenant system, you want to access a specific customer record (#1234) for a specific tenant (#5678). You have two approaches:
-
Infer the tenant ID from the current user:
/api/1.0/customers/1234 -
Explicitly include the tenant ID in the path:
/api/1.0/5678/customers/1234
I prefer the second approach since it makes the addressing absolute and the system more predictable. It also has the side effect of making it easier to support data sharing between tenants or making it possible for the same user account to access the data of multiple tenants. Obviously, you need some kind of protection mechanism that denies access to tenants that the user is not allowed to access.
However, there are also use cases where it makes more sense to infer contextual information from the current user. Take these resources for example:
-
Get the current user’s details:
/api/1.0/currentUser/details -
Change the current user’s password:
/api/1.0/currentUser/changePassword
Exposing single entities and operations on them is pretty straight forward. The approach I like to use is best explained by some examples:
-
GET /api/1.0/accounts: list all accounts in the system (filtering, sorting and pagination info can be passed in as query parameters) -
GET /api/1.0/accounts/1234: list the details of account #1234 -
PUT /api/1.0/accounts/1234: update the details of account #1234 -
POST /api/1.0/accounts: create a new account -
DELETE /api/1.0/accounts/1234: delete account #1234 -
PUT /api/1.0/accounts/1234/lock: lock account #1234
In some cases, this is not enough. For complex views, you may want to have a specialized REST API that returns aggregated DTOs in a single call. In this case, you should start by looking over your message formats. Can you compose your aggregates out of existing DTOs or do you need to define completely new structures? In this case it is helpful to have separate DTO classes in the frontend and in the backend because you can combine them in the way that makes the most sense. An aggregate that in the backend is constructed by combining many smaller DTOs could be deserialized into one single big DTO in the frontend.
Regardless of how you choose to structure your aggregates, you need a consistent way of naming and addressing your custom endpoints. You do not want to end up in a situation where one complex view uses one type of REST API and another view uses a completely different view. Here are a few examples:
-
GET /api/1.0/accounts/summary: list a summary of the user accounts -
GET /api/1.0/customers/1234/summary: list a summary of customer #1234 -
GET /api/1.0/agenda/day: day view of a calendar -
GET /api/1.0/agenda/week: week view of a calendar -
GET /api/1.0/agenda/month: month view of a calendar -
GET /api/1.0/agenda/custom/mySpecialView: a view of a calendar that has been specialized for one particular client -
PUT /api/1.0/globalSearch: system global search that accepts a complex query object as input
Reporting errors (and success)
Things do not always go according to plan. Errors - both caused by users and by the system itself - are inevitable and the REST API must be able to deal with them accordingly. There are two ways you can report that an error occurred:
-
Include information about whether the operation succeeded or not in the response of the request. This approach makes the most sense in a message bus like architecture where all messages are POSTed to a single REST resource. The response envelope could then include a status code and possible error message. A different HTTP status code than 200 would only be used to indicate that the server was not able to process the request at all.
-
Use the HTTP status codes and include any additional information as JSON or XML in the response body. This approach makes the most sense when you are accessing resources or performing operations by using different URLs
There are a lot of HTTP status codes and you only need to know a handful of them. The error code is enough for the client to know that something went wrong. For an improved user experience, you may want to include additional information in the body of the response that the client can parse and show to the user or store in a log.
| Status code |
Meaning |
When to use |
| 200 |
OK |
Successful operations that return data (such as GETs). |
| 201 |
Created |
Successful operations that create new data (such as POSTs). |
| 204 |
No Content |
Successful operations that do not return any data (such as DELETEs). |
| 400 |
Bad Request |
Bad syntax of the request, unsupported message format, data validation errors, etc. |
| 401 |
Unauthorized |
The user is not authenticated. |
| 403 |
Forbidden |
The user is authenticated, but does not have permission to access the resource or perform the operation. |
| 404 |
Not Found |
The user tried to access a resource or perform an operation that does not exist. This code can also be used instead of 403 if we want to hide the existence of the protected resource. |
| 409 |
Conflict |
Optimistic or pessimistic locking errors. |
| 500 |
Internal server error |
All other errors. |
User authentication
Finally, we are going to look at how to authenticate users. This very much depends on how you are going to implement the frontend. If your frontend includes native mobile applications or JavaScript applications that interact directly with your REST API, you need a way of authenticating the actual users of the system. In this case, my recommendation is to start by using existing authentication methods. Basic authentication or Digest authentication together with SSL/TLS are perfectly fine for this.
If your frontend also includes another system, such as a Vaadin server side application, you will need to support an authentication mechanism where the other system can perform operations on behalf of the actual users of the system. How you do this very much depends on your environment:
-
If the environment already has an authentication and authorization system in place, such as OAuth or Kerberos, it makes sense to plug into that.
-
If the backend and the frontend are trusted parties, just passing the user ID as an HTTP request header might be enough. For added security, client-side SSL authentication or API keys (a secret shared between the servers) can be used to verify the identities of both servers.
-
If the backend and the frontend are not trusted parties and you do not have an existing authentication system to rely on, you have a few alternatives (and all assume you have an encrypted channel):
-
A simple, though not very elegant solution is to keep the user’s credentials in the session and authenticate with them every time the backend is called. It works, but I am not comfortable with storing the user’s password longer than it is needed.
-
A more advanced approach is a token based system where the frontend receives a token from the backend when the user logs on. This token is then passed on with every call to the backend. The token should have an expiration date so that it cannot be misused for long in case it is compromised and it should be signed so that its integrity can be verified.
-
A word on service consumption
So far we have only discussed REST design and the server side of the backend. However, there are a few things worth mentioning regarding consuming REST services from a Vaadin frontend application.
The rule of thumb is quite simple: whenever you leave your Java VM to perform an operation, expect the operation to fail. Once the operation fails, you should not let it bring down the rest of your system.
In practice, the first step is to use timeouts everywhere. Use a timeout for connecting to your REST endpoint and a timeout for reading from it and keep these timeouts short and realistic.
The next step is to make sure your frontend application knows what to do when the timeouts occur. Should it automatically retry the request, fallback to a cached value or show an error message? While you are at it, remember to make sure your frontend knows how to deal with all the other error messages that your REST endpoint can return.
Finally, if you start to experience saturation, you should consider adding a circuit breaker to your frontend. Simply put, the circuit breaker will cause your requests to fail immediately if it deduces that it is not possible to process them without timing out. Once the load goes down, the circuit breaker will continue to process requests. You can try to create your own circuit breaker or rely on an existing framework such as Hystrix.
Conclusion
The freedom of protocol design that REST allows is a double-edged sword. On the one hand, it makes it possible to create an API that is optimized for your specific application. On the other hand, it is very easy to turn the API into an inconsistent mess.
When you start to design your API, you need to consider the following things:
-
What message format are you going to use (JSON, XML, something else)?
-
What will the REST resources be and how will they be addressed?
-
What HTTP methods will you use and for what purposes?
-
What error codes will you use and when?
-
How will the system be secured?
Once you know all this, you can get to work on the API. It should be possible to implement 90% of your API like this. For the remaining 10% it is OK to break your own rules, but in that case you have to keep the anomalies isolated so that they do not become your new standard.
Designing a REST API is an iterative process where you may need to go back and revisit some parts as you gain more knowledge of the system you are building. However, once a REST API goes live, you have limited possibilities to change it without releasing a new version of the API.