TL;DR: Vaadin was hardly SEO-friendly in the past. Not anymore, with the new Volga library.
Bookmarking pages
Bookmarking is as old as www itself. Being able to save an URL is part of the ADN of websites. Regarding web apps, this is somewhat different. For example, in an e-commerce webapp, while it does make sense to bookmark a specific product, bookmarking a specific step of the checkout process does not.
Following the shop example, here’s what happens in a traditional servlet-based context:
A servlet is mapped on a specific subcontext such as /product/*
When the URL /product/really-cool-product is called, the doGet() method of that servlet is called
The method parses the URL to read the really-cool-product part - which should be an unique key for the product
It delegates to a whole chain of components that loads the product from the datastore
It forwards to a JSP along with the relevant product data
This JSP generates the HTML
Single-Page Applications
Come SPAs. By definition, they serve all content under the same URL. This makes bookmarking specific pages of the application impossible because there are no pages per se. In general, SPAs handle this problem with fragment identifiers. The above URL becomes /product#really-cool-product, problem solved. In Vaadin, this directly translate to usage of the Page.getCurrent().setUriFragment() method or of the Navigator API.
Unfortunately, this doesn’t work at all with the crawling part of SEO. Fragments are not discriminatory parts of an URL: #really-cool-product and #another-cool-product do point to the same URL so bots such as Google Bot won’t crawl both.
The fragment identifier functions differently than the rest of the URI: namely, its processing is exclusively client-side with no participation from the web server.
-- Wikipedia
For a while Google recommended to use special “hashbang” style URLs (#!my-indexable-view), like what Navigator in Vaadin uses, and specially served SEO material for those views, but this was a tricky workaround and the approach is now deprecated by Google as well.
Distinct URLs for SPAs
Back to square one, both /product/really-cool-product and /product/another-cool-product paths are required. This problem is not unique to Vaadin, but common to all server- and client-side SPA frameworks. What is required is:
To have the client change the browser’s URL without full page reload
To have the server handle paths
In JavaScript, the answer is to use the History API. I assume everyone is familiar with the following snippet:
window.back();
window.go(-1);
This is however absolutely not standard. This should be replaced by the following:
window.history.back();
window.history.go(-1);
The history object implements the History API. It’s supported by all modern browsers. In particular, the API makes it possible to add entries in the browser history via thepushState() method, without actually doing full page loads.
Suppose http://mozilla.org/foo.html executes the following JavaScript:
This will cause the URL bar to display http://mozilla.org/bar.html, but won't cause the browser to load bar.html or even check that bar.html exists.
--Mozilla Developer Network
Note that Vaadin Directory contains the History wrapper library around the client-side API. It provides a way to manage the history object from server-side Vaadin code.
On the server-side, paths also need to be handled. In Vaadin apps, full URLs are accessible in UI.init() methods, from servlets or from e.g. BootstrapListeners. The History add-on also supports the Navigator API and View objects with full paths without hashbang-style URLs.
Beyond distinct URLs
Distinct URLs is only the emerged part of the iceberg regarding SEO.
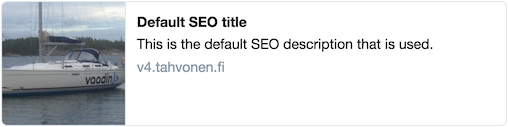
One wants to have dedicated meta headers for each dedicated URL, such as <title> and <meta name="description">. Even further, social medias have their own dedicated meta headers, e.g.:
Implementing the steps above from scratch in your Vaadin project is definitely not trivial. Rejoice, for comes Volga, a ready-to-use library that handles the brunt of things for you.
Set the VolgaDetails for the root path and provides bindings between a path and other VolgaDetails objects. This way, each specific path can be set their own VolgaDetails.
org.vaadin.volga.Volga
Holds the previously defined mappings
org.vaadin.volga.VolgaUI
Handles the initial configuration
org.vaadin.volga.SeoBootstrapListener
Fills page metadata headers from a VolgaDetails object
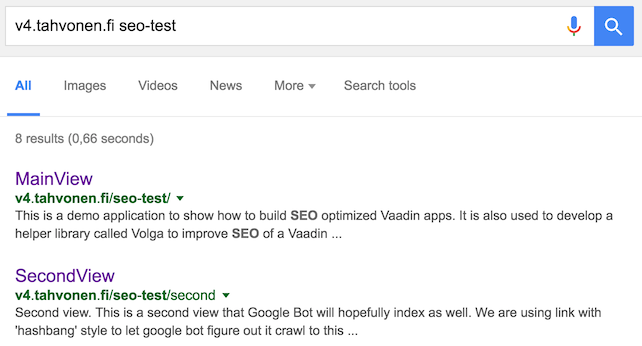
For more details, please check this example project on Github. It's deployed online and here are results shown on Google search that proves that it works.
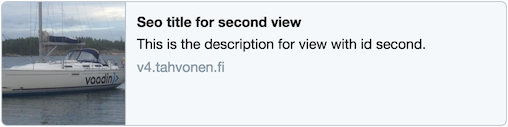
This works for Twitter as well:
Miscellaneous finishing touches
There are also a couple of other tricks to consider to help bots crawl Vaadin apps.
Use a robots.txt file
Use a sitemap.xml
Use basic links to navigate between views (see PushStateLink in History)
Use well-formed HTML, e.g. use proper <h1> elements instead of just styling headers bigger (see Header and RichText in Viritin)
Note, that GWT is currently failing to serve anything relevant for GoogleBot by default. A patch is available in Volga but it will be fixed in Vaadin itself soon
Don’t wait and make relevant parts of your app SEO-friendly with Volga now!
Nicolas Fränkel is a Software Architect with 15 years experience consulting for many different customers, in a wide range of contexts (such as telecoms, banking, insurances, large retail and public sector). Usually working on Java/Java EE and Spring technologies, but with narrower interests like Software Quality, Build Processes and Rich Internet Applications. Currently working for an eCommerce solution vendor leader. Also double as a teacher in universities and higher education schools, a trainer and triples as a book author.