Data Providers (Flow)
Tree Grid supports connecting to different types of data sources using hierarchical data providers. For simple use cases, it offers a built-in TreeData structure along with a ready-made TreeDataProvider, which together provide an easy way to create and manage hierarchies in memory. It also supports custom hierarchical data providers to fetch data from other sources, e.g. a database.
Tree Data Provider
The TreeData class is a simple, built-in structure for storing and managing hierarchical data in memory. It supports basic operations for manipulating the tree, such as adding items, moving them to a different parent, and removing them.
The TreeDataProvider class is a companion to TreeData. It wraps a TreeData instance and enables it to be used as a data source for a Tree Grid while also providing support for sorting, filtering, and lazy loading.
Both are available out of the box in Flow and can be used with Tree Grid like this:
Source code
Java
// Create a TreeData instance
TreeData<Folder> treeData = new TreeData<>();
// Create a TreeDataProvider backed by the TreeData instance
TreeDataProvider<Folder> treeDataProvider = new TreeDataProvider<>(
treeData,
HierarchicalDataProvider.HierarchyFormat.FLATTENED);
// Set the data provider to the Tree Grid
treeGrid.setDataProvider(treeDataProvider);|
Note
|
Using the |
Adding Items
The TreeData structure provides methods for adding both root-level and child items. In the example below, the TreeData#addRootItems(Collection<T> items) and TreeData#addItem(T parent, T child) methods are used to construct a simple folder hierarchy:
Source code
Java
// ├── Work
// │ └── Documents
// │ └── Invoices
// └── Family
Folder work = new Folder("Work");
Folder documents = new Folder("Documents");
Folder invoices = new Folder("Invoices");
Folder family = new Folder("Family");
treeData.addRootItems(work, family);
treeData.addItem(work, documents);
treeData.addItem(documents, invoices);The resulting tree structure can be navigated using the TreeData#getChildren(T parent) and TreeData#getParent(T item) methods:
Source code
Java
treeData.getChildren(new Folder("Documents")); // => List(Folder("Invoices"))
treeData.getParent(new Folder("Invoices")); // => Folder("Documents")
treeData.getChildren(new Folder("Family")); // => empty List
treeData.getParent(new Folder("Family")); // => null (root item)Moving Items within Tree
Once items are added to the TreeData, they can be moved to a different parent within the tree. The next example shows how the TreeData#setParent(item, newParent) method can be used together with Tree Grid’s drag-and-drop events to let users move folders around:
Source code
Java
// Allow dragging folders
treeGrid.setRowsDraggable(true);
treeGrid.setDropMode(GridDropMode.ON_TOP);
treeGrid.addDragStartListener(event -> {
// Store the dragged folder for use in the drop listener
draggedFolder = event.getDraggedItems().getFirst();
});
treeGrid.addDropListener(event -> {
event.getDropTargetItem().ifPresent((targetFolder) -> {
// Move the dragged folder under the target folder
treeData.setParent(draggedFolder, targetFolder);
// Refresh the Tree Grid to reflect the changes in the UI
treeDataProvider.refreshAll();
});
draggedFolder = null;
});Modifying the TreeData structure doesn’t automatically update the Tree Grid UI. To reflect such changes, you should always explicitly call the TreeDataProvider#refreshAll() method, as shown above.
Alternatively, if the hierarchy remains unchanged and only item properties are updated, you can use a more targeted method like TreeDataProvider#refreshItem(item) instead.
Removing Items
To remove items from the tree, you can use the TreeData#removeItem(item) method. It removes the given item along with all its children. The following example demonstrates how to delete the selected folder when Delete is pressed:
Source code
Java
// Allow selecting folders
treeGrid.setSelectionMode(SelectionMode.SINGLE);
// Add a keyboard shortcut listener for the Delete key
Shortcuts.addShortcutListener(treeGrid, () -> {
Folder selectedFolder = treeGrid.asSingleSelect().getValue();
if (selectedFolder != null) {
// Remove the selected folder from the TreeData
treeData.removeItem(selectedFolder);
// Refresh the Tree Grid to reflect the changes in the UI
treeDataProvider.refreshAll();
}
}, Key.DELETE);As before, make sure to call TreeDataProvider#refreshAll() to update the Tree Grid UI after making any structural changes to the TreeData.
Custom Data Providers
Conceptually, any hierarchical data provider, including TreeDataProvider, is a class that implements the HierarchicalDataProvider interface.
For convenience, Flow provides a related abstract base class AbstractHierarchicalDataProvider, which you can extend to create a custom hierarchical data providers. This class requires implementing the following methods:
Source code
Java
class CustomDataProvider extends AbstractHierarchicalDataProvider<T, F> {
@Override
public boolean isInMemory() { 1
// Your implementation here
}
@Override
public boolean hasChildren(T item) { 2
// Your implementation here
}
@Override
public int getChildCount(HierarchicalQuery<T, F> query) { 3
// Your implementation here
}
@Override
public Stream<T> fetchChildren(HierarchicalQuery<T, F> query) { 4
// Your implementation here
}
}-
The
isInMemorymethod indicates whether the data provider uses an in-memory data source. If it returnstrue, Tree Grid may use some additional optimizations. -
The
hasChildrenmethod returns whether the given item has child items and can therefore be expanded in the Tree Grid. -
The
getChildCountmethod returns the number of child items based on the query parameters. -
The
fetchChildrenmethod returns a stream of child items based on the query parameters.
When Tree Grid needs to load data, it calls the getChildCount and fetchChildren methods, passing a HierarchicalQuery object with parameters such as the requested range, the parent item whose children to load and other query details like sorting and filtering. The data provider’s implementation is then responsible for querying the data source based on these parameters and returning the results in one of the formats supported by Tree Grid.
The available formats and their trade-offs are described in the next section.
Hierarchy Formats
Tree Grid supports data providers that return hierarchical data in one of two formats: HierarchyFormat.NESTED or HierarchyFormat.FLATTENED.
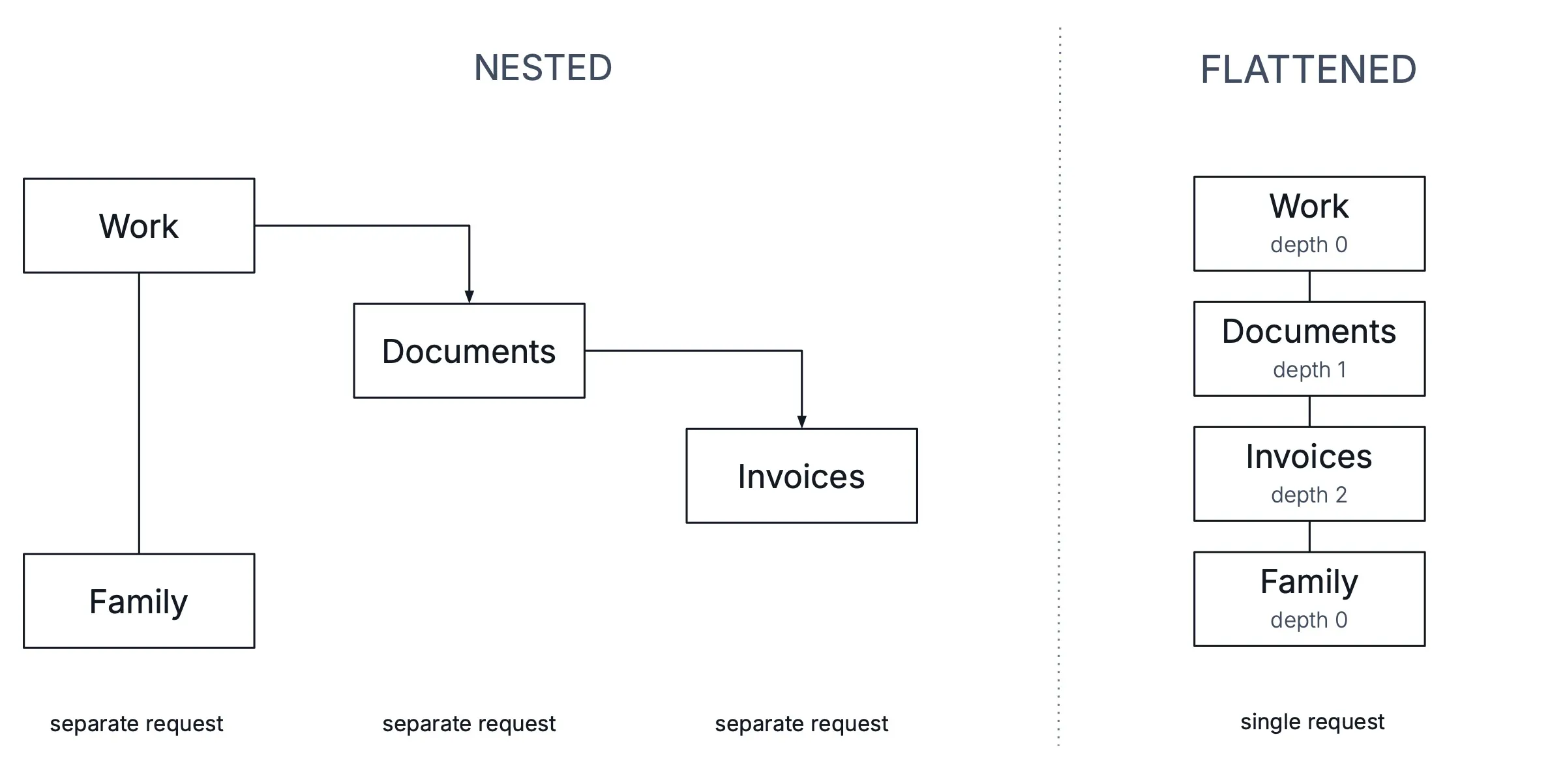
Both formats have their advantages and disadvantages. When implementing a custom hierarchical data provider, choose the format that best fits your use case and application requirements.
HierarchyFormat.NESTED (default)
The nested hierarchy format refers to a data provider implementation that, in each request, returns only the direct children of the requested parent item.
Tree Grid fills the viewport by sending requests to the data provider based on the current scroll position and viewport size. Each request includes a HierarchicalQuery object, where:
-
HierarchicalQuery#getParent()specifies the parent item whose direct children are to be fetched. -
HierarchicalQuery#getOffset()andHierarchicalQuery#getLimit()define the range of direct children to return.
If the returned children include expanded items that also fall within the visible range, Tree Grid sends additional requests to load their children, and so on. This creates a nested loading pattern where the hierarchy structure is discovered and cached progressively as the component is scrolled and more expanded items come into view.
Below is an example of a simple in-memory data provider using the nested hierarchy format and TreeData as the data source:
Source code
FolderDataProvider.java
class FolderDataProvider implements AbstractHierarchicalDataProvider<Folder, Void> {
public FolderTreeData folderTreeData = new FolderTreeData();
@Override
public boolean isInMemory() {
// Indicate that this data provider uses an in-memory data source.
return true;
}
@Override
public HierarchyFormat getHierarchyFormat() {
// Indicate that this data provider uses the nested hierarchy format.
// This is also the default value, so this method can be omitted.
return HierarchyFormat.NESTED;
}
@Override
public boolean hasChildren(Folder folder) {
// Return whether the given folder has child folders.
return folderTreeData.getChildren(folder).size() > 0;
}
@Override
public Stream<Folder> fetchChildren(HierarchicalQuery<Folder, Void> query) {
// Return the direct children of the requested parent folder.
// The query object also includes parameters for sorting and filtering,
// which can be applied here if needed.
return folderTreeData.getChildren(query.getParent()).stream()
.skip(query.getOffset()).limit(query.getLimit());
}
@Override
public int getChildCount(HierarchicalQuery<Folder, Void> query) {
// Return the number of direct children of the requested parent folder.
// The query object also includes parameters for filtering, which can
// be applied here if needed.
return folderTreeData.getChildren(query.getParent()).size();
}
}FolderTreeData.java
Folder.java
Advantages:
-
Simple to grasp and implement. Each request deals with one hierarchy level at a time while Tree Grid handles the rest, such as managing hierarchy traversal, caching, etc.
-
Each individual request is inherently lightweight, as it only needs to return direct children of a parent item.
Disadvantages:
-
The full size and structure of the tree remain unknown since determining them would require loading the entire hierarchy into memory, which isn’t efficient for this format. As a result, Tree Grid can’t restore the scroll position automatically after
HierarchicalDataProvider#refreshAll()because it resets the cached hierarchy state. -
Fast scrolling can skip over hierarchy levels, which makes this format less ideal for using with drag-and-drop.
-
While individual requests are lightweight, a large number of expanded items can result in many requests in a short time, which may affect performance if the data source isn’t optimized for this access pattern.
HierarchyFormat.FLATTENED
The flattened hierarchy format refers to a data provider implementation that returns the entire sub-tree of the requested parent item in a single, flat list, including all expanded descendants arranged in depth-first order: parent first, then its children, followed by their children, and so on.
To load the current viewport, Tree Grid sends a single request with a HierarchicalQuery object, where:
-
HierarchicalQuery#getParent()specifies the parent item whose sub-tree to be fetched as a flat list. Thenullvalue means the entire tree starting from the root items. -
HierarchicalQuery#getExpandedItemIds()provides a set of item IDs that are currently expanded. -
HierarchicalQuery#getOffset()andHierarchicalQuery#getLimit()define the slice of the flat list to return.
Additionally, the data provider must implement HierarchicalDataProvider#getDepth(T item) to return the depth for each item in the hierarchy. Tree Grid uses this information to indent items visually.
Below is an example of a simple in-memory data provider using the flattened hierarchy format and TreeData as the data source:
Source code
FolderDataProvider.java
class FolderDataProvider implements AbstractHierarchicalDataProvider<Folder, Void> {
public FolderTreeData folderTreeData = new FolderTreeData();
@Override
public boolean isInMemory() {
// Indicate that this data provider uses an in-memory data source.
return true;
}
@Override
public HierarchyFormat getHierarchyFormat() {
// Indicate that this data provider uses the flattened hierarchy format.
return HierarchyFormat.FLATTENED;
}
@Override
public boolean hasChildren(Folder folder) {
// Return whether the given folder has child folders.
return folderTreeData.getChildren(folder).size() > 0;
}
@Override
public Stream<Folder> fetchChildren(HierarchicalQuery<Folder, Void> query) {
// Return the flattened sub-tree of the requested parent folder based on
// the expanded folders.
return flatten(query.getParent(), query.getExpandedItemIds())
.skip(query.getOffset()).limit(query.getLimit());
}
@Override
public int getChildCount(HierarchicalQuery<Folder, Void> query) {
// Return the size of the flattened sub-tree of the requested parent
// folder based on the expanded folders.
return (int) flatten(query.getParent(), query.getExpandedItemIds())
.count();
}
@Override
public int getDepth(Folder folder) {
// Return the depth of the given folder in the hierarchy for Tree Grid
// to apply the correct indentation.
int depth = 0;
while ((folder = folderTreeData.getParent(folder)) != null) {
depth++;
}
return depth;
}
private Stream<Folder> flatten(Folder parent,
Set<Object> expandedFolderIds) {
// Build the parent folder's sub-tree based on the provided expanded
// folders. The result is a flat stream of folders in depth-first order.
// Filtering and sorting can also be applied here if needed. Keep in
// mind that sorting must be applied to each hierarchy level separately
// to preserve depth-first order in the final flat list.
return folderTreeData.getChildren(parent).stream().flatMap(child -> {
if (expandedFolderIds.contains(getId(child))) {
return Stream.concat(Stream.of(child),
flatten(child, expandedFolderIds));
} else {
return Stream.of(child);
}
});
}
}FolderTreeData.java
Folder.java
Advantages:
-
Tree Grid can get the full size of the tree and set the scroll container height upfront, which results in more predictable scrolling experience. This is essential when using features like drag-and-drop.
-
By re-fetching the full tree size,
HierarchicalDataProvider#refreshAll()can preserve the scroll position, avoiding unexpected jumps. -
Enables you to use more advanced techniques for querying data, e.g. Common Table Expressions (CTEs) in SQL databases to build the sub-tree in a single query.
Disadvantages:
-
More complex to implement, with potentially heavier queries since the hierarchy has to be reconstructed for every request.